| 목차 | |
| 1. | 정규화 |
| 2. | 정규화와 성능 |
| 3. | 반정규화 |
| 4. | 분산 데이터베이스 |
| 5. | 예제 문제 |
| 6. | 내용 요약 |
1. 정규화




2. 정규화와 성능



3. 반정규화





4. 분산 데이터베이스




5. 예제 문제
◎ 문제
▶ 1번

▶ 2번

▶ 3번

▶ 4번

▶ 5번

◎ 정답
▶ 1번
정답 : 4번
▶ 2번
정답 : 3번
▶ 3번
정답 : 4번
▶ 4번
정답 : 3번
▶ 5번
정답 : 2번
6. 내용 요약
■ 함수의 종속성
○ BCNF
- 복수의 후보키가 있고, 후보키들이 복합 속성이어야 하며, 서로 중첩되어야 함
■ 정규화의 문제점 예제
○ 제1정규화

- 속성을 보고 한 개의 속성으로 유일성을 만족할 수 있는지 확인함.
- 제품번호 + 주문번호가 식별자가 되면 엔터티의 유일성을 만족함.

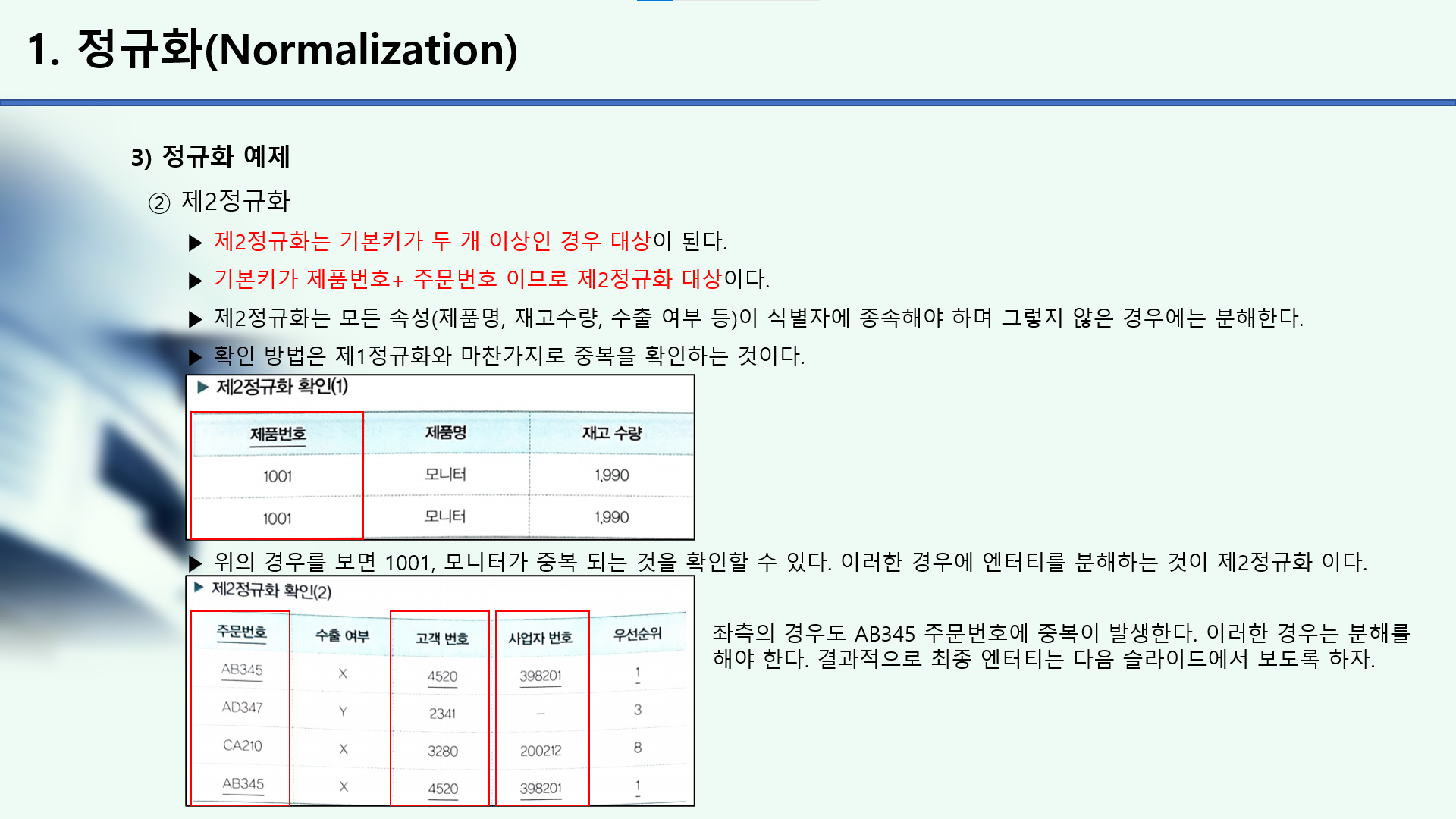
○ 제2정규화
- 제2정규화는 기본키가 두 개 이상인 경우 대상임
- 기본키가 제품번호+ 주문번호 이므로 제2정규화 대상임



○ 정규화의 문제점 예제
- 정규화는 데이터 조회(SELECT)시에 조인(Join)을 유발하기 때문에 CPU와 메모리를 많이 사용함
- 앞에서의 테이블은 직원과 부서 테이블에서 부서 코드가 같은 것을 찾는 것이다. 이것을 프로그램화한다면 중첩된 루프(Nested Loop)를 사용해야 함

- 이러한 구조는 데이터양이 증가하면 비교해야 하는 건수도 증가함
- 물론 실제로 위와 같은 비효율이 발생하지는 않는다. 이러한 문제를 해결하기 위해서 인덱스와 옵티마이저(Optimizer)가 있는 것임
- 옵티마이저(Optimizer)란? 옵티마이저는 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심 엔진임. 컴퓨터의 두뇌가 CPU인 것처럼 DBMS의 두뇌는 옵티마이저라고 할 수 있음
- Index는 RDBMS에서 검색 속도를 높이기 위한 기술임.TABLE의 컬럼을 색인화(따로 파일로 저장)하여 검색 시 해당 TABLE의 레코드를 Full Scan하는게 아니라 색인화 되어있는 INDEX 파일을 검색하여 검색속도를 빠르게 함
■ 정규화를 사용한 성능 튜닝
- 조인으로 인하여 성능이 저하되는 문제를 반정규화로 해결함.
- 반정규화는 데이터를 중복시킴
-----------------------------------시험 범위 X (2023년 개정) -----------------------------------
■ 반정규화
- 데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법임
- 반정규화는 조회(SELECT)속도를 향상시키지만, 데이터 모델의 유연성은 낮아짐
■ 반정규화를 수행하는 경우
○ 반정규화 절차

○ 클러스터링(Clustering)
- 클러스터링 인덱스라는 것은 인덱스 정보를 저장할 때 물리적으로 정렬해서 저장하는 방법이다.
- 따라서 조회 시에 인접 블록을 연속적으로 읽기 때문에 성능이 향상된다.
■ 반정규화 기법
1) 계산된 칼럼 추가

2) 테이블 수직분할


3) 테이블 수평분할


○ 파티션(Partition) 기법
- 데이터베이스에서 파티션을 사용하여 테이블을 분할할 수 있다. 파티션을 사용하면 논리적으로는 하나의 테이블이지만 여러 개의 데이터 파일에 분산되어서 저장된다.
- Range Partition : 데이터 값의 범위를 기준으로 파티션을 수행한다.
- List Partition : 특정한 값을 지정하여 파티션을 수행한다.
- Hash Partition : 해시함수를 적용하여 파티션을 수행한다.
- Composite Partition : 범위와 해시를 복합적으로 사용하여 파티션을 수행한다.
※ 해시 함수는 임의의 길이를 갖는 메시지를 입력 받아 고정된
길이의 해시 값을 출력하는 함수이다. 암호 알고리즘에는 키
가 사용되지만, 해시 함수는 키를 사용하지 않으므로 같은 입
력에 대해서는 항상 같은 출력이 나오게 된다. 이러한 해시함
수를 사용하는 목적은 메시지의 오류나 변조를 탐지할 수 있
는 무결성을 제공하기 위해 사용된다.
○ 파티션 테이블의 장점
- 데이터 조회 시에 액세스(Access) 범위가 줄어들기 때문에 성능이 향상된다.
- 데이터가 분할 되어 있기 때문에 I/O(Input/Output)의 성능이 향상된다.
- 각 파티션을 독립적으로 백업 및 복구가 가능하다.
4) 테이블 병합
○ Super type과 Subtype
- 고객 엔터티는 개인고객과 법인고객으로 분류된다. 이때 고객 엔터티는 슈퍼 타입이고 개인고객과 법인 고객은 서브타입이 된다. 즉, 부모와 자식 간의 관계가 나타난다.
- 슈퍼 타입과 서브타입의 관계는 배타적 관계와 포괄적 관계가 있는데, 배타적 관계는 고객이 개인고객이거나 법인고객인 경우를 의미한다. 포괄적 관계는 고객이 개인고객일 수도 있고 법인고객일 수도 있는 것이다.

■ 분산 데이터베이스
- 데이터베이스 시스템 구축 시에 한 대의 물리적 시스템에 데이터베이스 관리 시스템(DMBS)을 설치하고 여러 명의 사용자가 데이터베이스 관리 시스템에 접속하여 데이터베이스를 사용하는 구조를 중앙 집중형 데이터베이스 라고 한다.
- 또한 물리적으로 떨어진 데이터베이스에 네트워크로 연결하여 단일 데이터베이스 이미지를 보여주고 분산된 작업 처리를 수행하는 데이터베이스를 분산 데이터베이스 라고 한다.
- 분산 데이터베이스를 사용하는 고객은 시스템이 네트워크로 분산되어 있는지의 여부를 인식하지 못하면서, 자신만의 데이터베이스를 사용하는 것처럼 사용할 수 있다. 이처럼 데이터베이스는 투명성을 제공해야 한다.
○ 분산 데이터베이스의 투명성 종류

■ 분산 데이터베이스 설계 방식
- 분산 데이터베이스의 구축 방법에는 상향식 설계 방식과 하향식 설계 방식 2가지가 있다.
① 상향식 설계 방식
; 지역 스키마 작성 후 향후 전역 스키마를 작성하여 분산 데이터베이스를 구축한다.
② 하향식 설계 방식
; 전역 스키마 작성 후 해당지역 사상 스키마를 작성하여 분산 데이터베이스를 구축한다.

- 분산 데이터베이스를 하향식 접근방식으로 구축한다는 것은 기업 전체의
전사 데이터 모델을 수렴하여 전역 스키마를 생성하고, 그 다음 각 지역별
로 지역 스키마를 생성하여 분산 데이터베이스를 구축하는 것이다.
상향식 접근방식은 지역별로 데이터베이스를 구축한 후에 전역 스키마로
통합하는 것이다.
- 분산 데이터베이스를 구축하거나 운영할 때 동일한 데이터베이스 관리
시스템으로 분산 데이터베이스를 구축하는 것은 크게 어렵지 않다. 하지
만 기업에 여러 종류의 데이터베이스 관리 시스템이 있으면 이기종 데이
터베이스 관리 시스템으로 연동 해야 한다. 이기종 데이터베이스시스템으
로 연동하기 위해서는 데이터베이스 미들웨어(ODBC, JDBC)를 사용해야
한다.
○ 분산 데이터베이스 장점과 단점

※ 반정규화부터 배우는 내용들은 2023년 개정 내용과 다른 내용임, 즉 시험에 나오지 않는 내용도 있기에 참고용으로만 보는 것을 추천함 (다음 블로그부터는 2023년 개정 버전으로, 처음부터 다시 내용 요약을 함)
'자격증 > SQLD' 카테고리의 다른 글
| SQLD 데이터 모델링의 이해(6~10) - 11일차 (0) | 2024.10.21 |
|---|---|
| SQLD 데이터 모델링의 이해(1~5) - 10일차 (0) | 2024.10.16 |
| SQLD 데이터 모델링의 이해 - 8일차 (0) | 2024.10.11 |
| SQLD 데이터 모델링의 이해 - 7일차 (0) | 2024.10.10 |
| SQLD 데이터 모델링의 이해 - 6일차 (0) | 2024.10.09 |