| 목차 | |
| 9. | 서브쿼리 |
| 10. | 집합연산자 |
| 11. | 그룹 함수 |
| 12. | 윈도우 함수 |
9. 서브쿼리
● 서브쿼리
- 하나의 SQL 문안에 포함되어 있는 또 다른 SQL 문을 말함
- 반드시 괄호로 묶어야 함
● 서브쿼리 사용 가능한 곳
1) SELECT 절.
2) FROM 절
3) WHERE 절
4) HAVING 절
5) ORDER BY 절
6) 기타 DML(INSERT, DELETE, UPDATE) 절
** GROUP BY 절 사용 불가
● 서브 쿼리 종류
1. 동작하는 방식에 따라
1) UN-CORRELATED(비연관) 서브쿼리
2) CORRELATED(연관) 서브쿼리
2. 위치에 따라
1) 스칼라 서브쿼리
- SELECT에 사용하는 서브쿼리
- 서브쿼리 결과를 마치 하나의 컬럼처럼 사용하기 위해 주로 사용
** 문법

2) 인라인뷰
- FROM 절에 사용하는 서브쿼리
- 서브쿼리 결과를 테이블처럼 사용하기 위해 주로 사용
** 문법

3) WHRER 절 서브쿼리
- 가장 일반적인 서브쿼리
- 비교 상수 자리에 값을 전달하기 위한 목적으로 주로 사용(상수항의 대체)
- 리턴 데이터의 형태에 따라 단일행 서브쿼리. 다중 행 서브쿼리, 다중 컬럼 서브쿼리, 상호연관 서브쿼리로 구분.
** 문법

● WHERE 절 서브쿼리 종류
1) 단일행 서브쿼리
- 서브쿼리 결과가 1개의 행이 리턴되는 형태
- 단일행 서브쿼리 연산자 종류

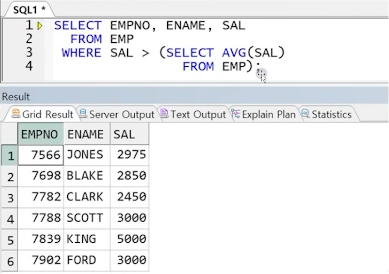
예제) EMP 테이블에서 전체 직원의 급여 평균보다 높은 평균을 받는 직원의 정보 출력
STEP1) 비교대상(전체 직원 급여 평균) 확인

STEP2) 메인쿼리의 비교 상수 자리에 서브쿼리 결과 전달
2) 다중 행 서브쿼리
- 서브쿼리 결과가 여러 행이 리턴되는 형태
- '=', '>', '<'와 같은 비교 연산자 사용불가(여러 값이랑 비교할 수 없는 연산자들)
- 서브쿼리를 하나로 요약하거나 다중 행 서브쿼리 연산자를 사용
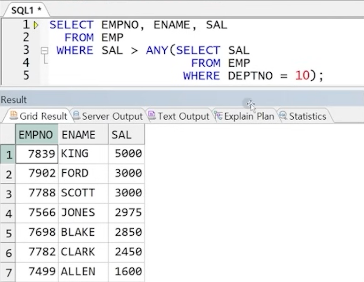
** 다중 행 서브쿼리 연산자

예제) ALL과 ANY 비교
> ALL(2000, 3000) : 최대값(3000)보다 큰 행들 반환
< ALL(2000, 3000) : 최솟값(2000)보다 작은 행들 반환
> ANY(2000, 3000) : 최솟값(2000)보다 큰 행들 반환
< ANY(2000, 3000) : 최대값(3000)보다 작은 행들 반환
예제) 다중 행 서브쿼리 연산자 오류 (서브쿼리 결과가 여러 개일 경우 = 연산자와 대소 비교 불가)
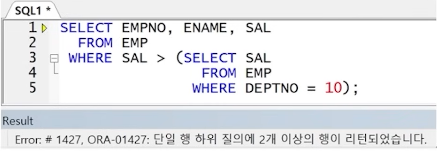
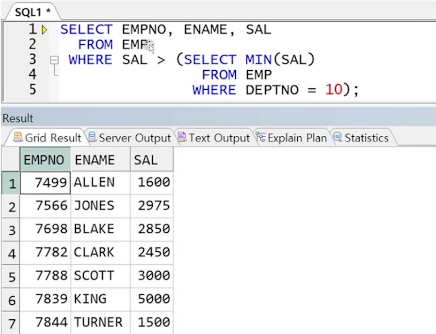
** 해결 1 : 서브쿼리 결과를 하나의 행의 결과가 되도록 변경
** 해결 2 : 다중 행 서브쿼리 연산자로 변경
3) 다중 컬럼 서브쿼리
- 서브쿼리 결과가 여러 컬럼이 리턴되는 형태
- 메인쿼리와의 비교 컬럼이 2개 이상
- 대소 비교 전달 불가(두 값을 동시에 묶어 대소비교 할 수 없음)
예제) EMP 테이블에서 부서별 최대 급여자 확인
STEP1) 부서별 최대 급여 확인
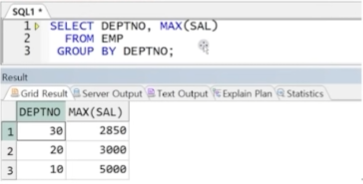
STEP2) 메인쿼리에 비교 대상으로 서브쿼리 결과 전달
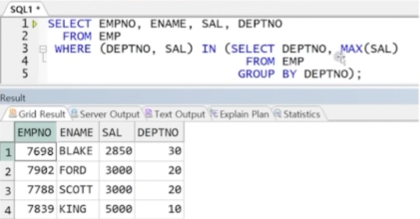
-> 부서별 최대 급여가 여러 값이 나오므로 비교 시에는 다중 행 연산자인 IN을 사용(= 사용 시 에러 발생)
4) 상호연관 서브쿼리
- 메인쿼리와 서브쿼리의 비교를 수행하는 형태
- 비교할 집단이나 조건은 서브쿼리에 명시(메인쿼리절에는 서브쿼리 컬럼이 정의되지 않았기 때문에 에러 발생)
예제) EMP 테이블에서 부서별로 해당 부서의 평균급여보다 높은 급여를 받는 사원 정보
** 에러 발생 다중 컬럼 서브쿼리는 동시 두 컬럼에 대한 대소비교 불가

** 해결) 대소 비교할 컬럼을 메인쿼리에, 일치 조건을 서브쿼리에 전달
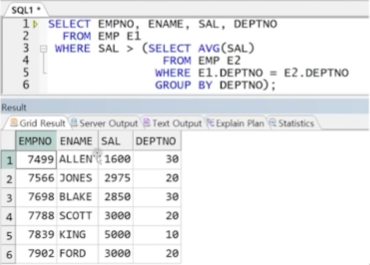
-> 메인쿼리와 결과적으로 비교해야 할 컬럼은 SAL과 DEPTNO인데, 그 중 SAL에 대한 대소비교 전에 먼저 비교할 부서(DEPTNO) 정보가 확정돼야 함
-> 먼저 비교할 DEPTNO 값을 서브쿼리에 전달
-> 메인쿼리에는 서브쿼리의 테이블 정보가 없으므로(순서상 메인쿼리부터 해석) E.DEPTNO = D.DEPTNO 조건은 사용불가
** 상호연관 서브쿼리 연산 순서
1) 메인쿼리 테이블 READ
2) 메인쿼리 WHERE 절 확인(SAL 확인)
3) 서브쿼리 테이블 READ
4) 서브쿼리 WHERE 절 확인(다시 21.DEPTNO 요구)
5) E1.DEPTNO 값을 서브쿼리의 DEPTNO 컬럼과 비교하여 조건절 완성
6) 위 조건에 성립하는 행의 그룹연산 결과 확인(AVG(SQL))
7) 위 결과를 메인쿼리에 전달하여 해당 조건을 만족하는 행만 추출
※ 상호연관 서브쿼리 사용 시 GROUP BY 생략 가능
● 인라인뷰(Inline View)
- 쿼리 안의 뷰의 형태로 테이블처럼 조회할 데이터를 정의하기 위해 사용
- 테이블명이 존재하지 않기 때문에 다른 테이블과 조인 시 반드시 테이블 별칭 명시(단독으로 사용하는 경우 불필요)
- WHERE 절 서브쿼리와 다르게 서브쿼리 결과를 메인 쿼리의 어느 절에서도 사용할 수 있음
- 인라인뷰의 결과와 메인쿼리 테이블과 조인할 목적으로 주로 사용
- 모든 연산자 사용 가능
예제) EMP 테이블에서 부서별 최대 급여자를 출력하되, 최대 급여와 함께 출력
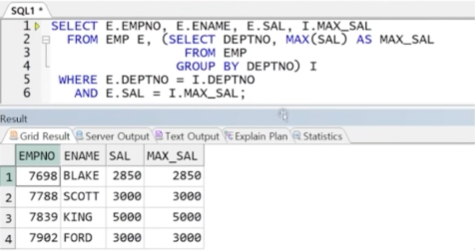
-> 인라인뷰에서의 함수에 의한 출력 결과(MAX(SAL))는 컬럼 별칭을 통해 메인쿼리에 전달
예제) EMP 테이블에서 부서별로 해당 부서의 평균 급여보다 높은 급여자를 출력하되, 평균 급여와 함께 출력
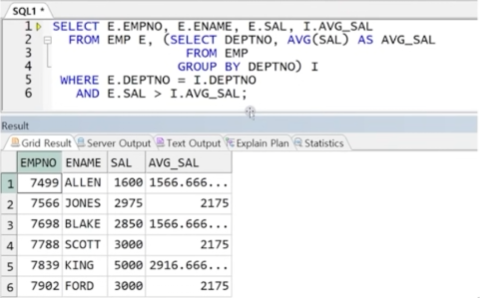
● 스칼라 서브쿼리
- SELECT 절에 사용하는 쿼리로, 마치 하나의 컬럼처럼 표현하기 위해 사용 (단, 하나의 출력 대상만 표현 가능)
- 각 행마다 스칼라 서브쿼리 결과가 하나여야 함(단일행 서브쿼리 형태)
- 조인의 대체 연산
- 스칼라 서브쿼리를 사용한 조인 처리 시 OUTER JOIN이 기본(값이 없더라도 생략되지 않고 NULL로 출력됨)
예제) EMP의 각 직원의 사번, 이름과 부서이름을 출력(부서이름을 스칼라 서브쿼리로)
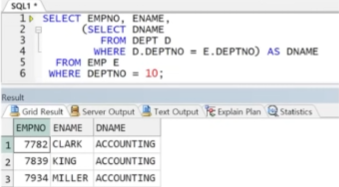
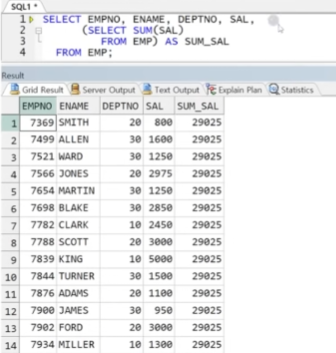
예제) EMP의 각 직원의 사번, 이름, 부서번호, 급여와 함께 급여 총합을 출력(총합을 스칼라 서브쿼리로)
예제) 서브쿼리와 아우터 조인
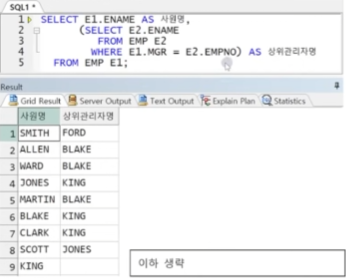
-> KING의 경우 MGR 컬럼 값이 NULL이므로 MGR = EMPNO에 만족하는 E2.ENAME 값이 없지만, 스칼라 서브쿼리는 무조건 메인쿼리절이 출력하는 대상에 대해 항상 값을 리턴해야 하므로 생략되지 않고 NULL로 출력됨
● 서브쿼리 주의 사항
- 특별한 경우(TOP-N 분석 등)을 제외하고는 서브쿼리절에 ORDER BY 절을 사용 불가
- 단일 행 서브쿼리와 다중 행 서브쿼리에 따라 연산자의 선택이 중요
예제) 서브 쿼리에 ORDER BY 전달 시 에러 발생

10. 집합 연산자
● 집합 연산자
- SELECT 문 결과를 하나의 집합으로 간주, 그 집합에 대한 합집합, 교집합, 차집합 연산
- SELECT 문과 SELECT 문 사이에 집합 연산자 정의
- 두 집합의 컬럼이 동일하게 구성되어야 함(각 컬럼의 데이터 타입과 순서 일치 필요)
- 전체 집합의 데이터타입과 컬럼명은 첫번째 집합에 의해 결정됨
● 합집합
- 두 집합의 총합(전체) 출력
- UNION과 UNION ALL 사용 가능
1) UNION
- 중복된 데이터는 한 번만 출력
- 중복된 데이터를 제거하기 위해 내부적으로 정렬 수행
- 중복된 데이터가 없을 경우는 UNION 사용 대신 UNION ALL 사용(불필요한 정렬 발생할 수 있으므로)
2) UNION ALL
- 중복된 데이터도 전체 출력
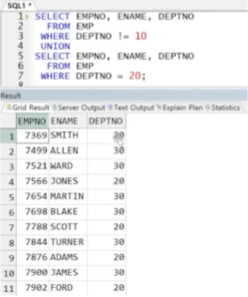
예제) 10번 부서 소속이 아닌 직원 정보와 20번 소속 직원 정보가 각각 분리되었다고 가정할 때 두 집합의 합집합
UNION 결과)
● 교집합
- 두 집합 사이에 INTERSECT
- 두 집합의 교집합(공통으로 있는 행) 출력
예제) 10번 부서 정보와 20번 부서 정보가 각각 분리되어있다고 가정할 때 두 집합의 교집합
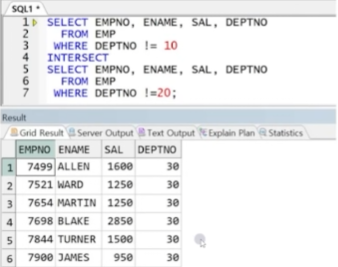
-> 부서 번호가 10번이 아닌 집합은 20, 30번 이고 20번이 아닌 부서원은 10, 30번 부서원이므로 두 집합의 교집합인 30번 부서원 정보만 출력됨
● 차집합
- 두 집합 사이에 MINUS 전달
- 두 집합의 차집합(한 쪽 집합에만 존재하는 행) 출력
- A-B와 B-A는 다르므로 집합의 순서 주의!
예제) 10번이 아닌 부서 정보와 20번 부서 정보가 각각 분리되어있다 가정할 때 두 집합의 차집합
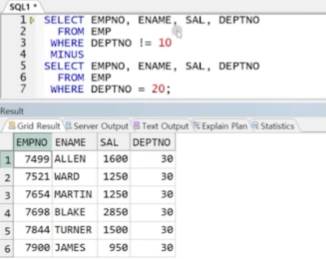
-> 부서 번호가 10번이 아닌 (20, 30)번인 집합에서 20번 집합을 빼면 30번 부서원 집합만 출력됨
● 집합 연산자 사용 시 주의 사항
1. 두 집합의 컬럼 수 일치
2. 두 집합의 컬럼 순서 일치
3. 두 집합의 각 컬럼의 데이터 타입 일치
4. 각 컬럼의 사이즈는 달라도 됨
5. 개별 SELECT 문에 ORDER BY 전달 불가(GROUP BY 전달 가능)
예제) 두 집합의 컬럼의 데이터 타입이 다른 경우 에러 발생
아래와 같은 EMP_T1 테이블이 있다고 가정, EMP와의 합집합 출력
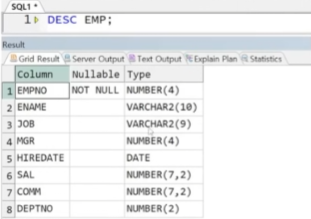
-> EMP 테이블의 각 컬럼별 데이터 타입
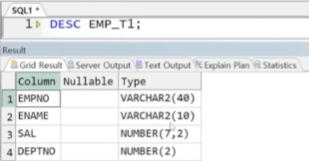
-> EMP_T1 테이블의 각 컬럼별 데이터 타입
** 에러)

-> 에러 발생(EMPNO 컬럼 데이터 타입 서로 다름)
** 해결)
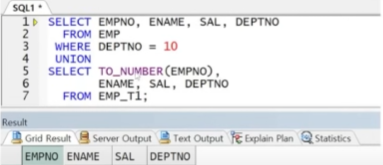
-> 두 집합의 EMPNO 컬럼의 데이터 타입이 다르므로 한 쪽으로 맞춰줄 필요 있음
예제) 집합 연산자와 ORDER BY의 사용
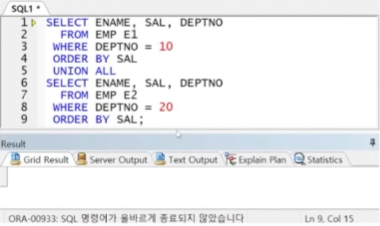
※ 개별 쿼리에 ORDER BY 절 전달 불가
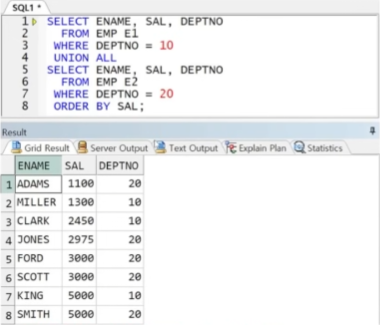
※ 집합 연산자 전체 결과에 ORDER BY 절 전달 가능
11. 그룹 함수
● 그룹 함수
- 숫자 함수 중 여러 값을 전달하여 하나의 요약 값을 출력하는 다중 행 함수
- 수학 / 통계 함수들(기술통계 함수)
- GROUP BY 절에 의해 그룹별 연산 결과를 리턴함
- 반드시 한 컬럼만 전달
- NULL은 무시하고 연산
● COUNT
- 행의 수를 세는 함수
- 대상 컬럼은 *또는 단 하나의 컬럼만 전달 가능(* 사용 시 모든 컬럼의 값이 NULL일 때만 COUNT 제외)
- 문자, 숫자, 날짜 컬럼 모두 전달 가능
- 행의 수를 세는 경우 NOT NULL 컬럼을 찾아 세는 것이 좋음(PK 컬럼)
** 문법

예제) 각 컬럼의 COUNT 결과
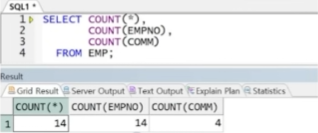
-> NULL을 포함한 컬럼은 전체 행의 수와 다르게 출력됨
● SUM
- 총합 출력
- 숫자 컬럼만 전달 가능
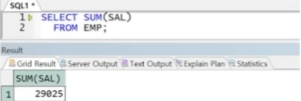
예제) 급여의 전체 총합
● AVG
- 평균 출력
- 숫자 컬럼만 전달 가능
- NULL을 제외한 대상의 평균을 리턴하므로 전체 대상 평균 연산 시 주의
** 문법

예제) 평균 계산 결과
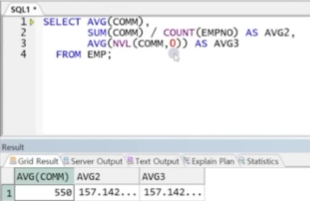
-> AVG를 사용하면 NULL을 제외한 나머지에 대한 평균(4명에 대한) 리턴, 공식에 의해 직접 계산한 평규능ㄴ 14명에 대한 평균
-> NVL 함수를 사용하여 NULL을 0으로 치환 후 평균을 구하면 총 14명에 대한 평균과 같아짐
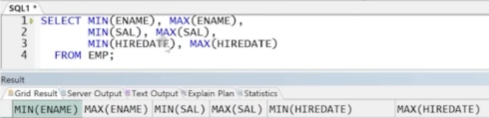
● MIN / MAX
- 최대, 최소 출력
- 날짜, 숫자, 문자 모두 가능(오름차순 순서대로 최소, 최대 출력)
** 문법

예제) 각 컬럼의 최대, 최소

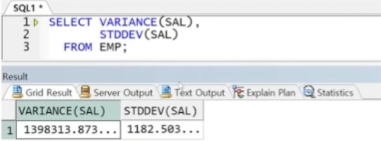
● VARIANCE / STDDEV
- 분산과 표준편차
- 표준편차는 분산의 루트값
** 문법

예제) 분산과 표준편차
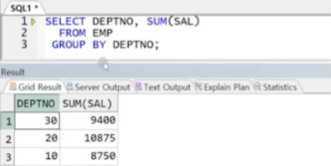
● GROUP BY FUNCTION
- GROUP BY 절에 사용하는 함수
- 여러 GROUP BY 결과를 동시에 출력(합집합)하는 기능
- 그룹핑 할 그룹을 정의(전체 소계 등)
예제) 본 GROUP BY 기능 : 그룹별 연산값만 출력되므로 전체 소계와 함께 출력될 수 없음
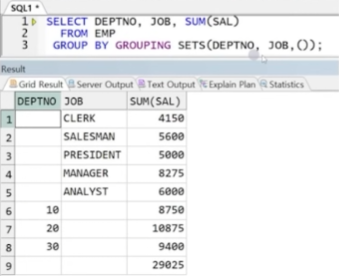
1. GROUPING SETS(A, B, ...)
- A 별, B 별 그룹 연산 결과 출력
- 나열 순서 중요하지 x
- 기본 출력에 전체 총계는 출력되지 X
- NULL 혹은 () 사용하여 전체 총합 출력 가능
예제) DEPTNO 별 SAL의 총합 결과와 JOB 별 SAL의 총합 결과의 합집합
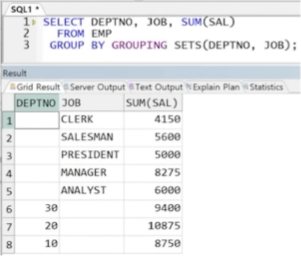
-> GROUPING SETS에 나열한 대상에 대해 각 GROUP BY의 결과를 출력해 줌
** UNION ALL로 대체 가능
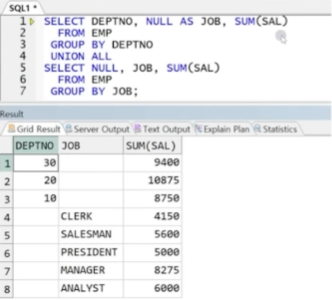
예제) 부서별 급여 총합과, 업무별 급여 총합, 그리고 전체 급여의 합을 출력
2. ROLLUP(A,B)
- A 별, (A B)별, 전체 그룹 연산 결과 출력
- 나열 대상의 순서가 중요함
- 기본적으로 전체 총계가 출력됨
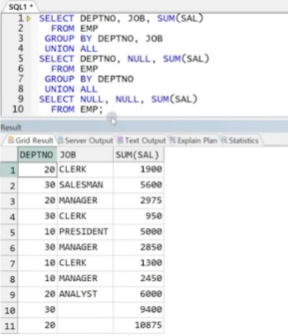
예제) ROLLUP(DEPTNO, JOB) -> DEPTNO 별, (DEPTNO, JOB) 별, 전체 연산 결과 출력
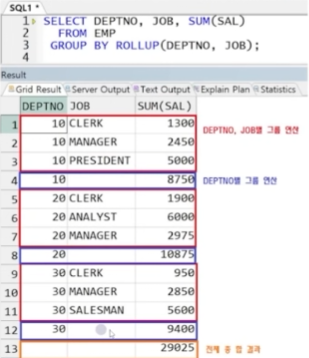
** UNION ALL로 대체 가능
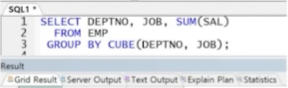
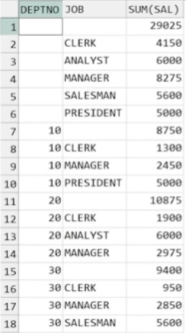
3. CUBE(A,B)
- A 별, B별, (A,B)별, 전체 그룹 연산 결과 출력됨
- 그룹으로 묶을 대상의 나열 순서 중요하지 않음
- 기본적으로 전체 총계가 출력됨
예제) DEPTNO 별, JOB 별, (DEPTNO, JOB)별, 전체 급여의 총합 출력
UNION ALL로 대체)
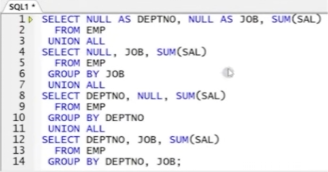
GROUPING SETS로 대체)

12. 윈도우 함수
● WINDOW FUNCTION
- 서로 다른 행의 비교나 연산을 위해 만든 함수
- GROUP BY를 쓰지 않고 그룹 연산 가능
- LAG, LEAD, SUM, AVG, MIN, MAX, COUNT, RANK
** 문법

** PARTITION BY 절 : 출력할 총 데이터 수 변화 없이 그룹 연산 수행할 GROUP BY 컬럼
** ORDER BY 절
- PANK의 경우 필수(정렬 컬럼 및 정렬 순서에 따라 순위 변화)
- SUM, AVG, MIN, MAX, COUNT 등은 누적값 출력 시 사용
** ROWS | RANGE BETWEEN A AND B
- 연산 범위 설정
- ORDER BY 절 필수
※ PARTITION BY, ORDER BY, ROWS... 절 전달 순서 중요(ORDER BY를 PARTITION BY 전에 사용 불가)
예제) 그룹 함수 오류(윈도우 함수가 필요한 이유)
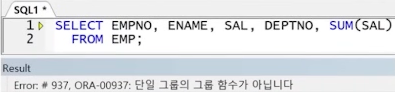
-> 전체를 출력하는 컬럼과 그룹 함수 결과는 함께 출력할 수 없음
● 그룹 함수의 형태
- SUM, COUNT, AVG, MIN, MAX 등
- OVER 절을 사용하여 윈도우 함수로 사용 가능
- 반드시 연산할 대상을 그룹 함수의 입력값으로 전달
** 문법

1) SUM OVER()
- 전체 총합, 그룹별 총합 출력 가능
예) 각 직원 정보와 함께 급여 총합 출력
** 에러 : 각 직원 정보와 급여 총합(그룹 함수 결과)을 동시에 출력 시도 시 에러 발생
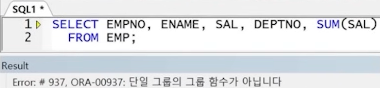
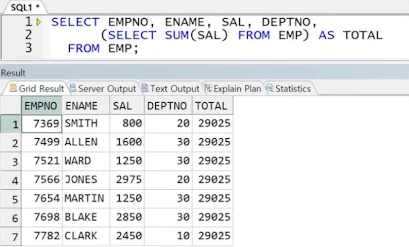
** 해결 1 : 서브쿼리 사용(스칼라 서브쿼리)
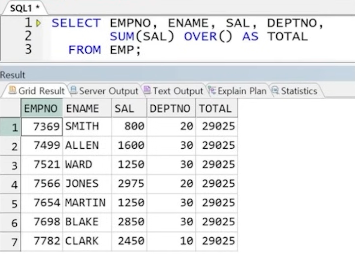
** 해결 2 : 윈도우 함수 사용
2. AVG OVER() : SUM과 동일하게 사용
예제) 각 직원 정보와 해당 직원이 속한 부서의 평균 급여 출력
3. MIN / MAX OVER() : SUM과 동일하게 사용
예제) 각 직원 정보와 해당 직원이 속한 부서의 최대급여를 함께 출력

4. COUNT : SUM과 동일하게 사용
** 윈도우 함수의 연산 범위 : 집계 연산 시 행의 범위 설정 가능
1. ROWS, RANGE 차이
1) ROWS : 값이 같더라도 각 행씩 연산
2) RANGE : 같은 값의 경우 하나의 RANGE로 묶어서 동시 연산(DEFAULT)
2. BETWEEN A AND B
A) 시작점 정의
- CURRENT ROW : 현재 행부터
- UNBOUNDED PRECEDING : 처음부터(DEFAULT)
- N PRECEDING : N 이전부터
B) 마지막 시점 정의
- CURRENT ROW : 현재 행까지(DEFAULT)
- UNBOUNDED FOLLOWING : 마지막까지
- N FOLLOWING : N 이후까지
예제) RANGE_TEST 테이블에서의 범위 설정에 따른 누적합
** CASE1) RANGE 범위 전달(DEFAULT) : 값이 같을 경우 같은 범위로 취급하여 동시 연산
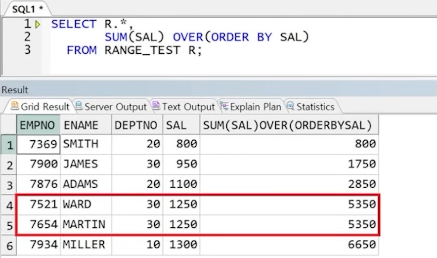
** CASE2) ROWS 범위 설정 시 : 각 행 별로 연산 수행
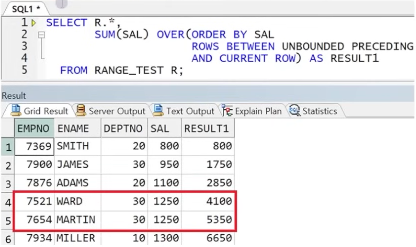
** CASE3) BETWEEN A AND B 수정 시
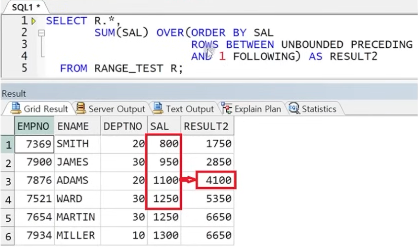
-> UNBOUNDED PRECEDING AND 1 FOLLOWING : 각 행마다 누적합 계산 시 처음부터 다음 행까지 연산
● 순위 관련 함수
1) RANK(순위)
1-1) RANK WITHIN GROUP
- 특정값에 대한 순위 확인(RANK WITHIN)
- 윈도우함수가 아닌 일반함수
** 문법

예) EMP에서 급여가 3000이면 전체 급여 순위가 얼마?
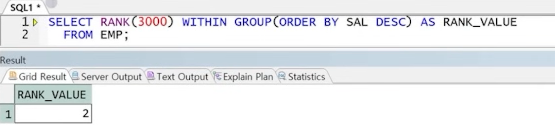
1-2) RANK() OVER()
- 전체 중 / 특정 그룹 중 값의 순위 확인
- ORDER BY 절 필수
- 순위를 구할 대상을 ORDER BY 절에 명시(여러 개 나열 가능)
- 그룹 내 순위 구할 시 PARTITION BY 절 사용
** 문법

예) 각 직원의 급여의 전체 순위(큰 순서대로)
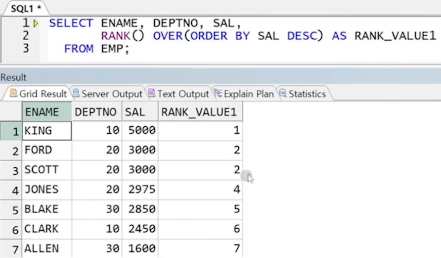
예) 각 직원 이름, 부서 번호, 급여, 부서별 급여 순위(큰 순서대로)
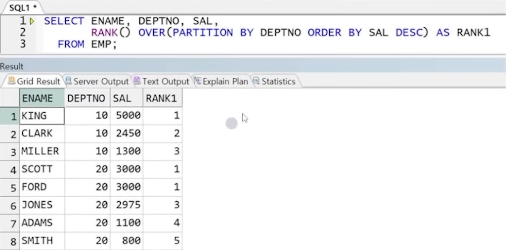
2) DENSE_RANK
- 누적순위
- 값이 같을 때 동일한 순위 부여 후 다음 순위가 바로 이어지는 순위 부여 방식
ex) 1 등이 5명이더라도 그 다음 순위가 2 등
3) ROW_NUMBER
- 연속된 행 번호
- 동일한 순위를 인정하지 않고 단순히 순서대로 나열한대로의 순서 값 리턴
예제) RANK, DENSE_RANK, ROW_NUMBER 비교
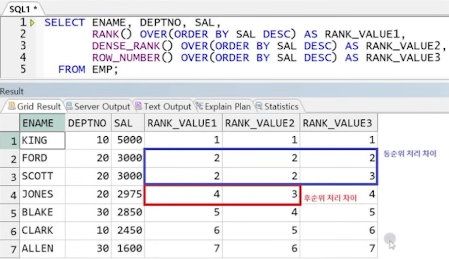
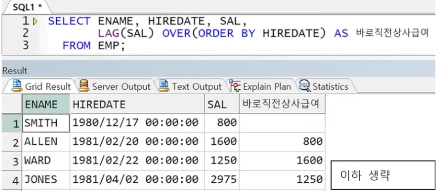
● LAG, LEAD
- 행 순서대로 각각 이전 값(LAG), 이후 값(LEAD) 가져오기
- ORDER BY 절 필수
** 문법

예) EMP에서 바로 이전 입사자와 급여 비교
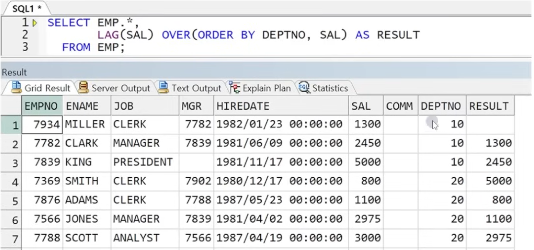
참고) 이전 / 이후 값 가져올 때 이전 값이 같더라도 항상 행의 순서대로 이전, 이후 하나를 가져옴 따라서 사용자가 이전 / 이후 값을 가져올 원하는 행 배치를 ORDER BY를 통해 충분히 전달한 후 이전 / 이후 값을 가져오면 됨
● FIRST_VALUE, LAST_VALUE
- 정렬 순서대로 정해진 범위에서의 처음 값, 마지막 값 출력
- 순서와 범위 정의에 따라 최솟값, 최댓값 리턴 가능
- PARTITION BY, ORDER BY 절 생략 가능
** 문법

예제) FIRST_VALUE를 사용한 최소, 최대 출력

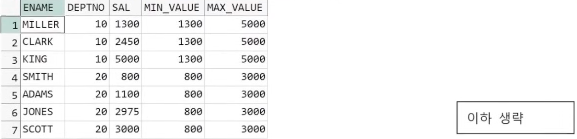
예제) LAST_VALUE를 사용한 최소, 최대 출력
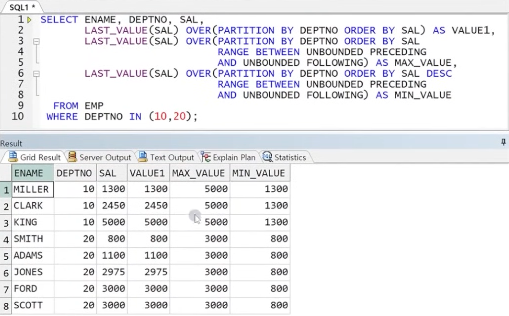
● NTILE
- 행을 특정 컬럼 순서에 따라 정해진 수의 그룹으로 나누기 위함 함수
- 그룹 번호가 리턴됨
- ORDER BY 필수
- PARTITION BY를 사용하여 특정 그룹을 또 원하는 수 만큼 그룹 분리 가능
- 총 행의 수가 명확히 나눠지지 않을 때 앞 그룹의 크기가 더 크게 분리됨
ex) 14명 3개 그룹 분리 시 -> 5, 5, 4로 나뉨
** 문법

예제) NTILE을 사용한 그룹 분리
● 비율관련 함수
1) RATION_TO_REPORT
- 각 값의 비율 리턴(전체 비율 또는 특정 그룹 내 비율 가능)
- ORDER BY 사용 불가
** 문법

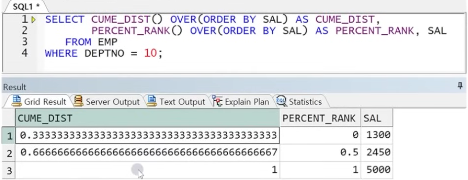
2) CUME_DIST : 각 행의 수에 대한 누적비율
- 특정 값이 전체 데이터 집합에서 차지하는 위치를 백분위수로 계산하여 출력
- ORDER BY를 사용하여 누적비율을 구하는 순서 정할 수 있음
- ORDER BY 필수
- 값이 3개이면 1 / 3 = 0.33부터 시작
** 문법

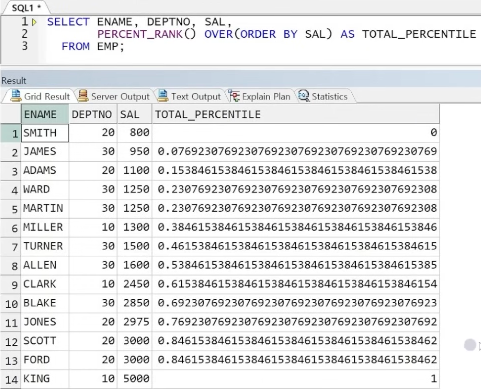
3) PERCENT_RANK
- PERCENTILE(분위수) 출력
- 전체 COUNT 중 상대적 위치 출력(0~1 범위 내)
- ORDER BY 필수
** 문법

예제) CUME_DIST와 PERCENT_RANK 비교
예제) 누적 비율 비교
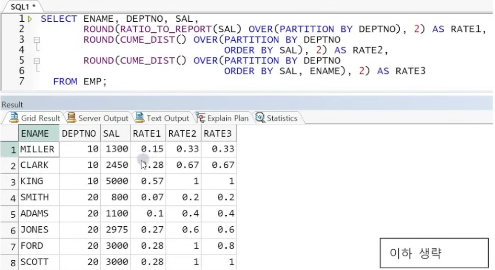
-> RATE2 : SAL에 대해서만 순서 정렬 후 RANGE로 누적비율을 구하므로 FORD와 SCOTT의 급여 누적비율이 같아짐(SAL 값이 같으니까 하나의 범위로 처리)
-> RATE3 : ORDER BY로 SAL, ENAME의 순서를 정의하므로 두 값이 모두 같을 때만 RANGE 처리하게 됨 => FORD와 SCOTT이 SAL 값이 같더라도 ENAME 값에 의해 두 행의 범위가 달라지므로 각각 연산됨
-> CUME_DIST는 RATIO_TO_REPORT처럼 비율을 계산할 값을 지정하지 않는다. 따라서 특정 값이 아닌, 각 행이 전체 혹은 PARTITON 내에 차지하고 있는 비율을 의미함(MILLER는 10번 부서원 총 3 명 중 1 명의 비율을 의미)
예제) PERCENT_RANK 예제
※ 출처 : 홍쌤의 데이터랩 - SQLD
'자격증 > SQLD' 카테고리의 다른 글
| SQLD SQL 기본 및 활용(17~18) - 16일차 (0) | 2024.11.10 |
|---|---|
| SQLD SQL 기본 및 활용(13~16) - 15일차 (0) | 2024.11.09 |
| SQLD SQL 기본 및 활용(5~8) - 13일차 (0) | 2024.11.03 |
| SQLD SQL 기본 및 활용(1~4) - 12일차 (0) | 2024.10.25 |
| SQLD 데이터 모델링의 이해(6~10) - 11일차 (0) | 2024.10.21 |