| 목차 | |
| 13. | Top N 쿼리 |
| 14. | 계층형 질의와 셀프 조인 |
| 15. | PIVIOT 절과 UNPIVIOT 절 |
| 16. | 정규 표현식 |
13. Top N 쿼리
● TOP N QUERY
- 페이징 처리를 효과적으로 수행하기 위해 사용
- 전체 결과에서 특정 N 개 추출
예) 성적 상위자 3 명
● TOP-N 행 추출 방법
1. ROWNUM
2. RANK
3. FETCH
4. TOP N(SQL Server)
● ROWNUM
- 출력된 데이터 기준으로 행 번호 부여
- 절대적인 행 번호가 아닌 가상의 번호이므로 특정 행을 지정할 수 없음(=연산 불가)
- 첫번째 행이 증가한 이후 할당되므로 '>' 연산 사용 불가(0 은 가능)
예제) ROWNUM 을 출력 형태

예제) ROWNUM 잘못된 사용 1

-> 크다 조건 전달 불가
예제) ROWNUM 잘못된 사용 2

-> 항상 불변하는 절대적 번호가 아니므로 '=' 연산자 단독 전달 불가
예제) ROWNUM 올바른 사용

-> EQAUL 비교 시 작다(<)와 함께 사용하면 1 부터 순서대로 뽑을 수 있기 때문에 출력 가능함
-> 정렬 순서에 따라 출력되는 ROWNUM 이 달라짐
예제) EMP 테이블에서 급여가 높은 순서대로 상위 5 명의 직원 정보 출력
** 잘못된 예
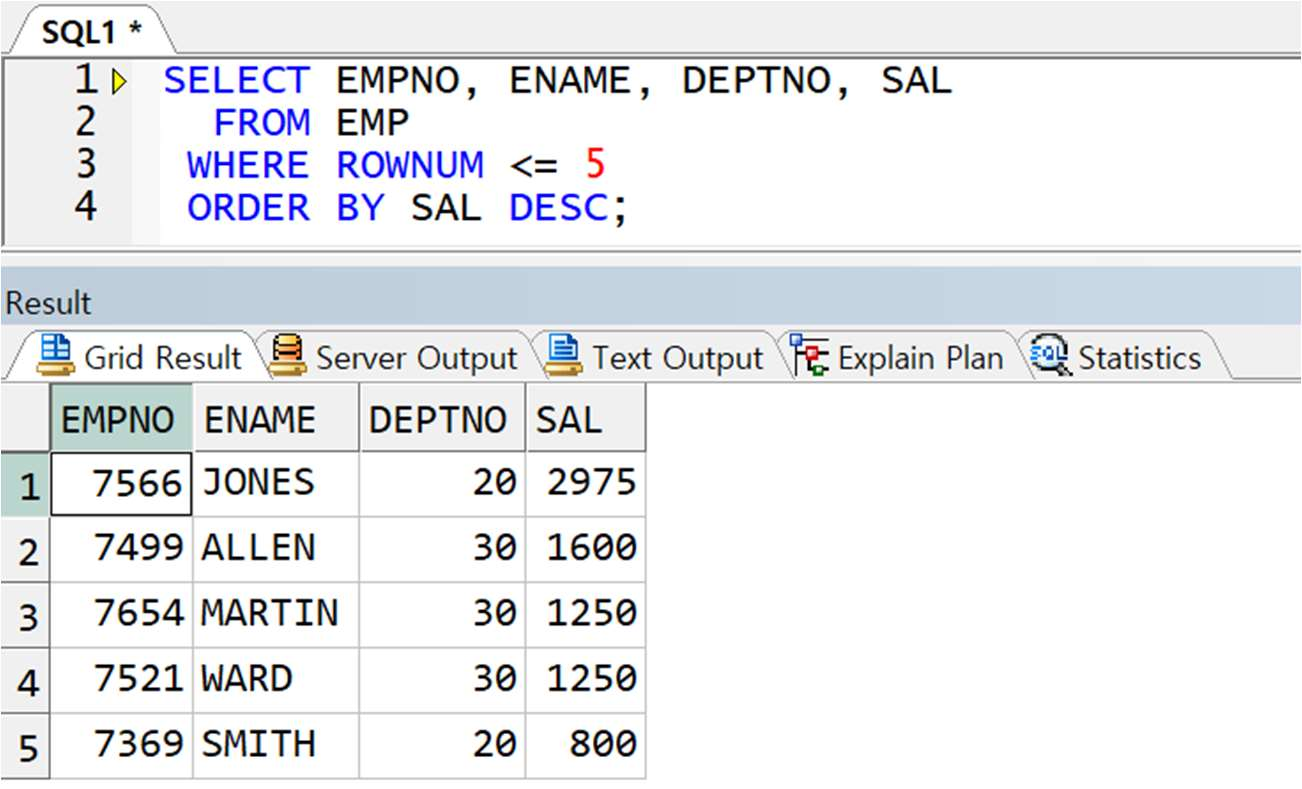
-> 실제로 상위 5 명 출력 안됨(급여최대가 5000 임)
-> 추출 원리 : WHERE 절에 의해 먼저 5 개를 추출 뒤 이 결과 집합에 대해 정렬 수행
** 해결 : 먼저 서브쿼리를 사용하여(인라인뷰) SAL 에 대해 내림차순 정렬을 해놓고 상위 5 개 가져옴
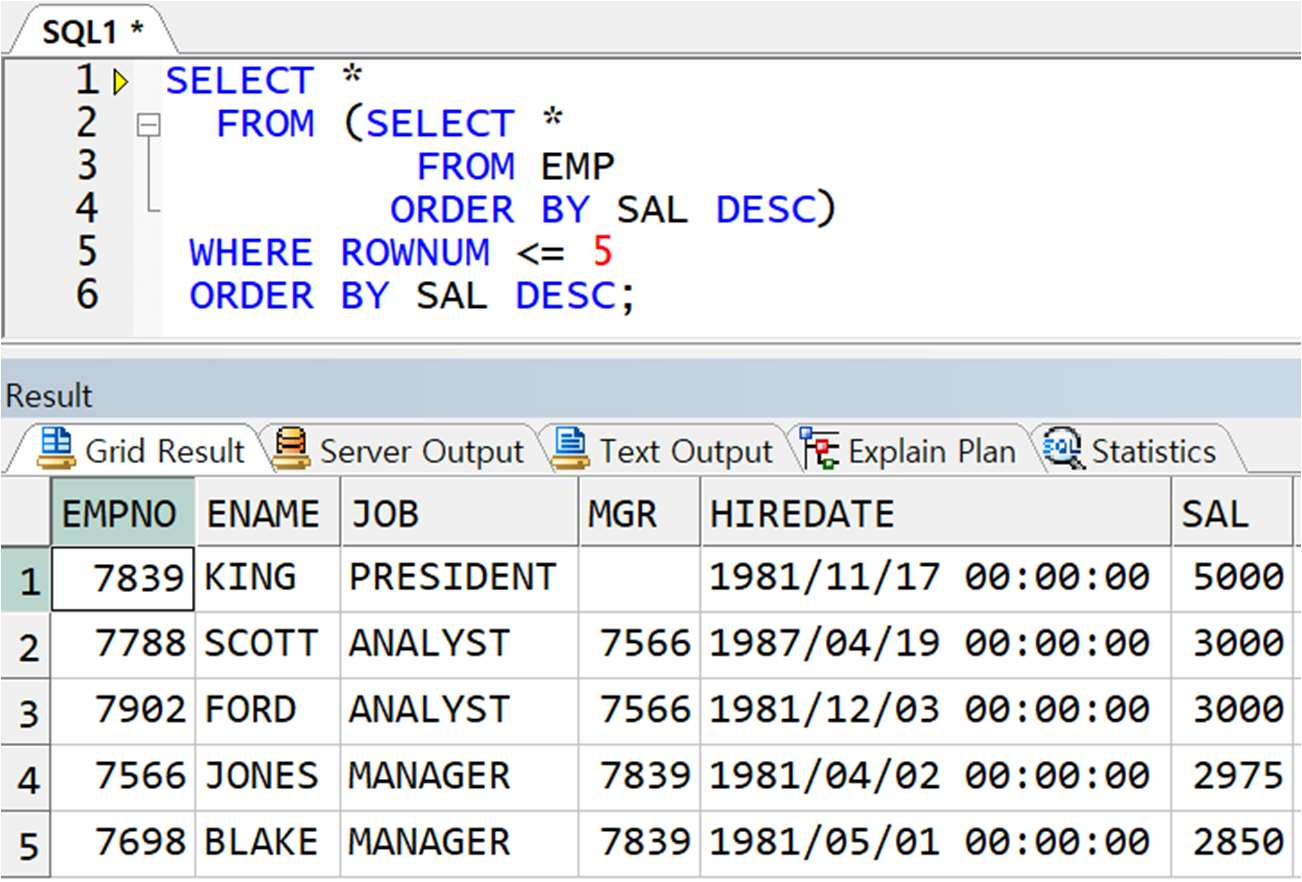
-> 즉 ROWNUM 이 결정되기 전에 먼저 데이터 정렬순서를 바꿔놓는 방법
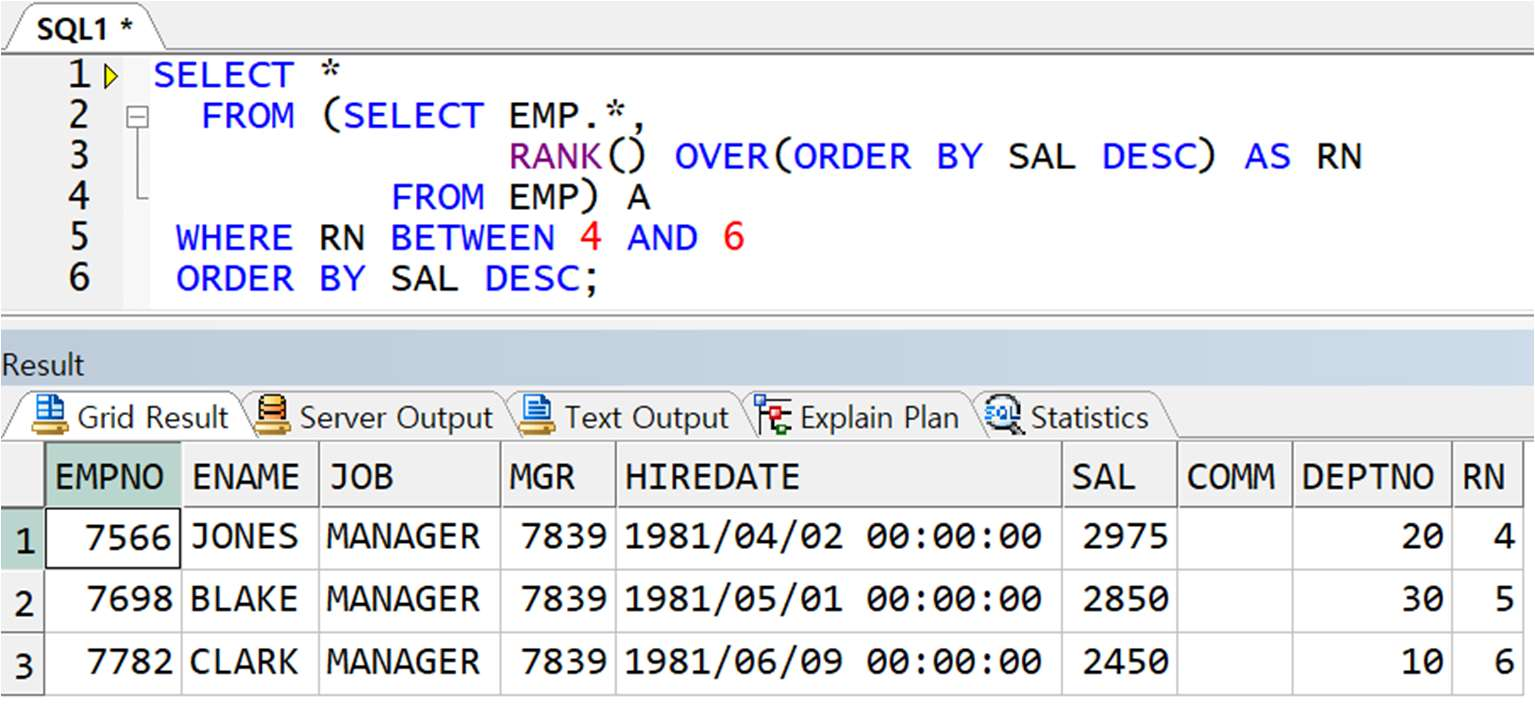
예제) EMP 테이블에서 급여가 높은 순서대로 4 ~ 6 번째 해당하는 직원 정보 출력
** 잘못된 예
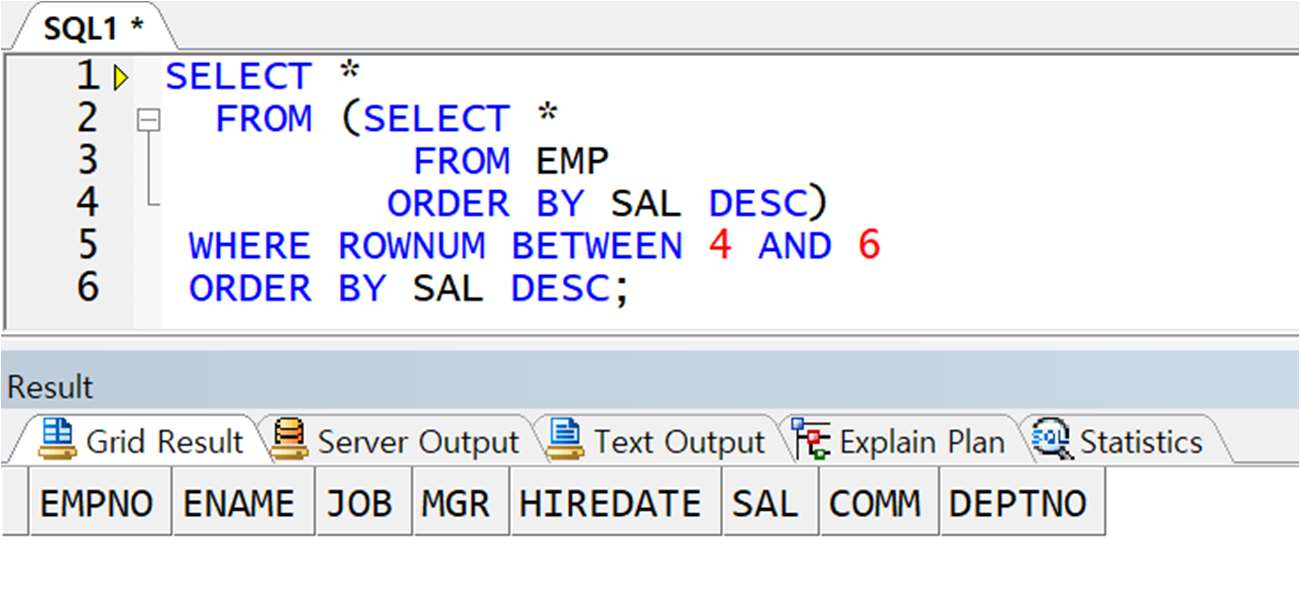
-> ROWNUM 시작 값(1)이 정의되지 않았으므로 1 을 건너뛰고 그 다음 행 번호에 대한 추출 불가
** 해결 : 인라인 뷰에서 각 행마다의 순위를 직접 부여
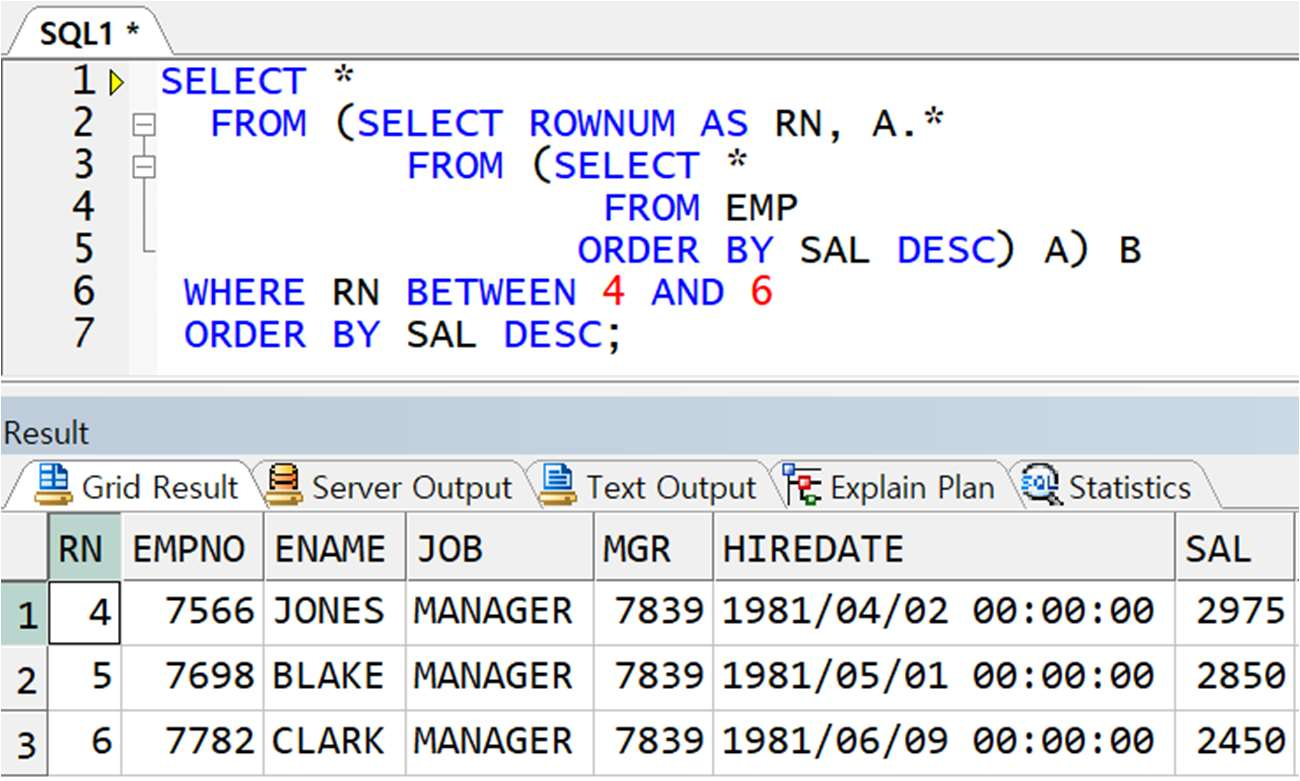
-> 서브쿼리를 통해 얻은 결과에 ROWNUM 을 다시 부여하여 새로운 테이블인 것처럼 사용(인라인 뷰)
** 해결 : 윈도우 함수의 RANK 사용
● FETCH 절
- 출력될 행의 수를 제한하는 절
- ORACLE 12C 이상부터 제공(이전버전에는 ROWNUM 주로 사용)
- SQL Server 사용 가능
- ORDER BY 절 뒤에 사용(내부 파싱 순서도 ORDER BY 뒤)
** 문법
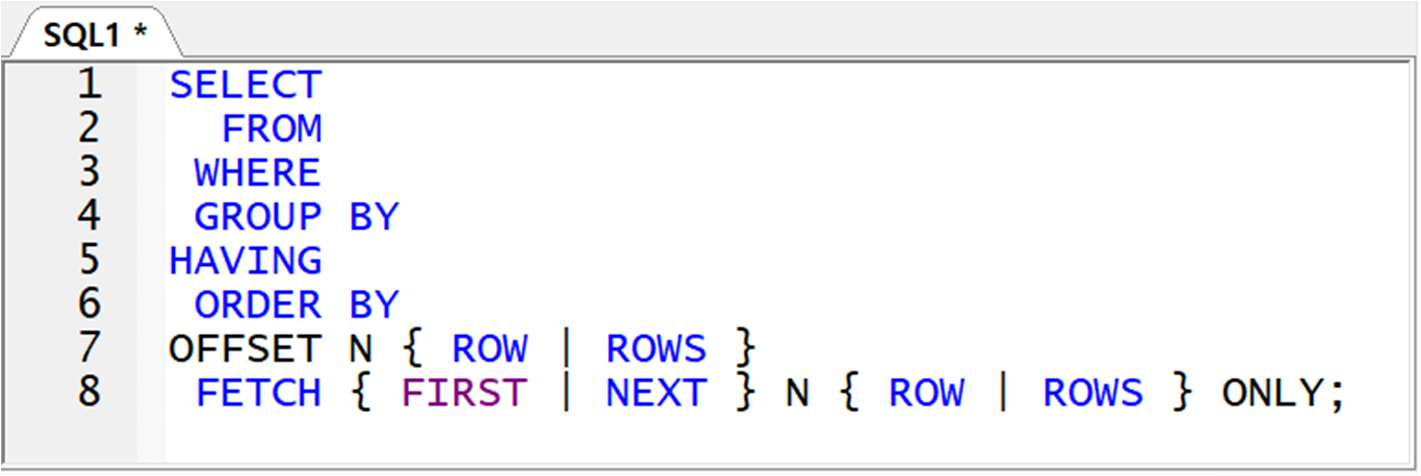
- OFFSET : 건너뛸 행의 수
ex) 성적 높은 순 1 등 제외, 나머지 3 명
- N : 출력할 행의 수
- FETCH : 출력할 행의 수를 전달하는 구문
- FIRST : OFFSET 을 쓰지 않았을 때 처음부터 N 행 출력 명령
- NEXT : OFFSET 을 사용했을 경우 제외한 행 다음부터 N 행 출력 명령
- ROW | ROWS : 행의 수에 따라 하나일 경우 단수, 여러 값이면 복수형(특별히 구분하지 않아도 됨)
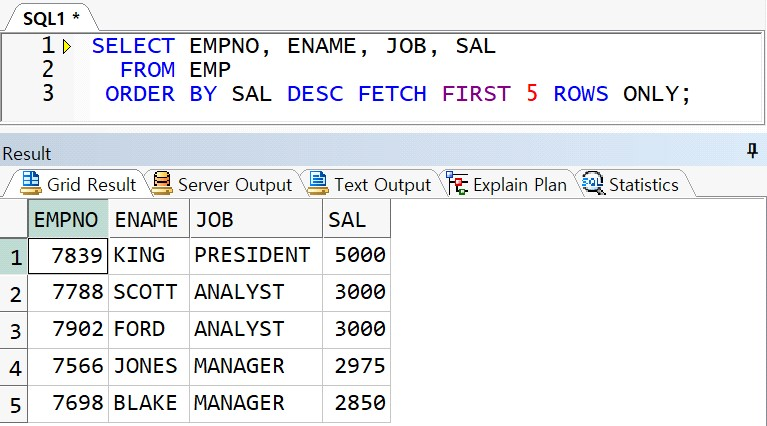
예제) EMP 에서 SAL 순서대로 상위 5 명(19C 에서 실행)
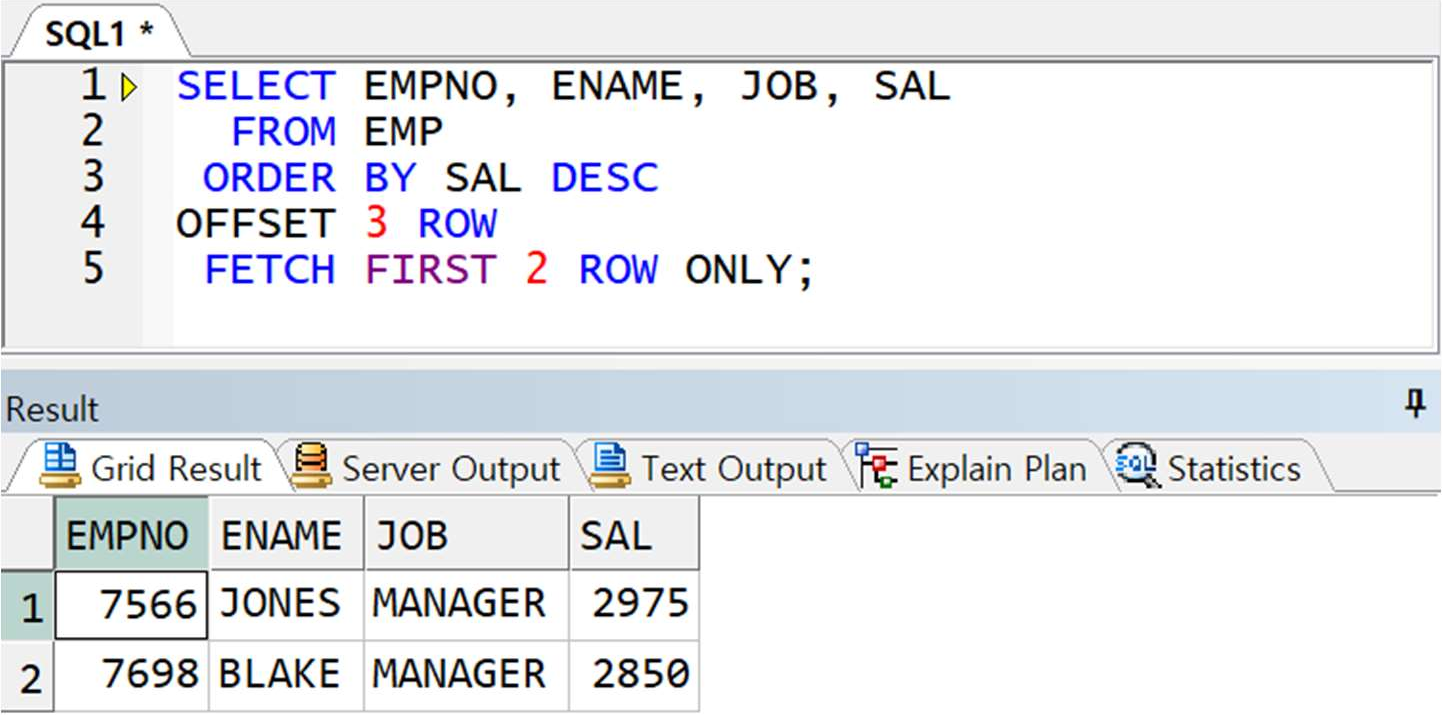
예제) EMP 테이블에서 급여가 높은 순서대로 4 ~ 5 번째 해당하는 직원 정보 출력
● TOP N 쿼리
- SQL Server 에서의 상위 n 개 행 추출 문법
- 서브쿼리 사용 없이 하나의 쿼리로 정렬된 순서대로 상위 n 개 추출 가능
- WITH TIES 를 사용하여 동순위까지 함께 출력 가능
** 문법

예제) EMP 테이블의 상위 급여자 2 명 출력(SQL Server 에서 수행)
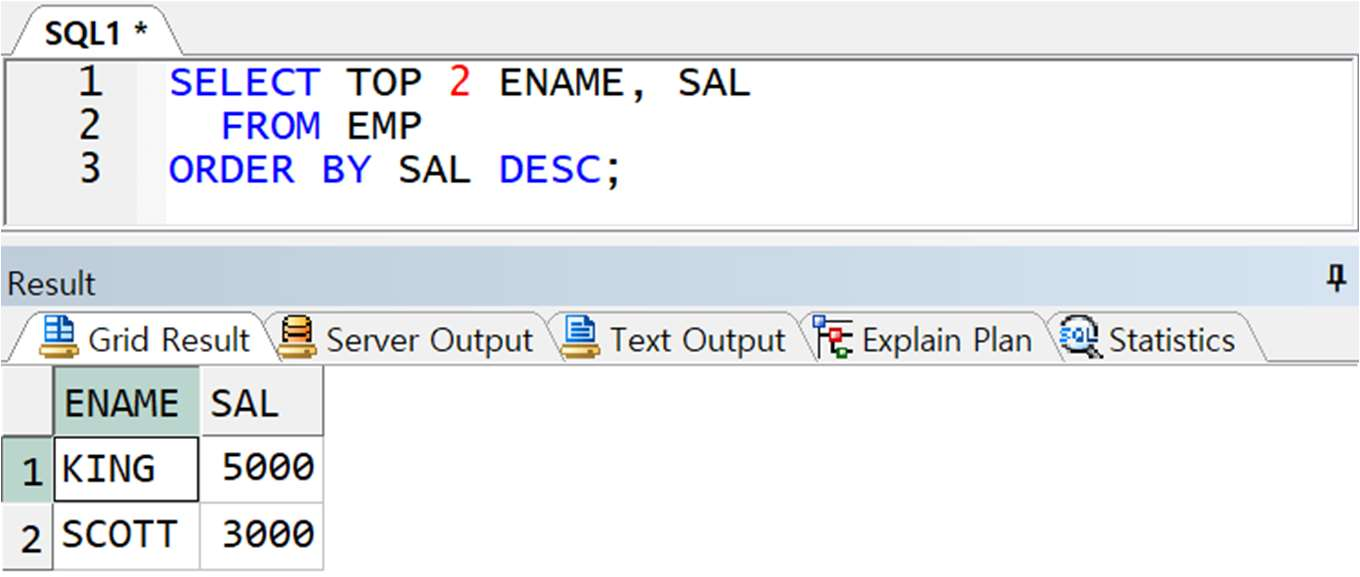
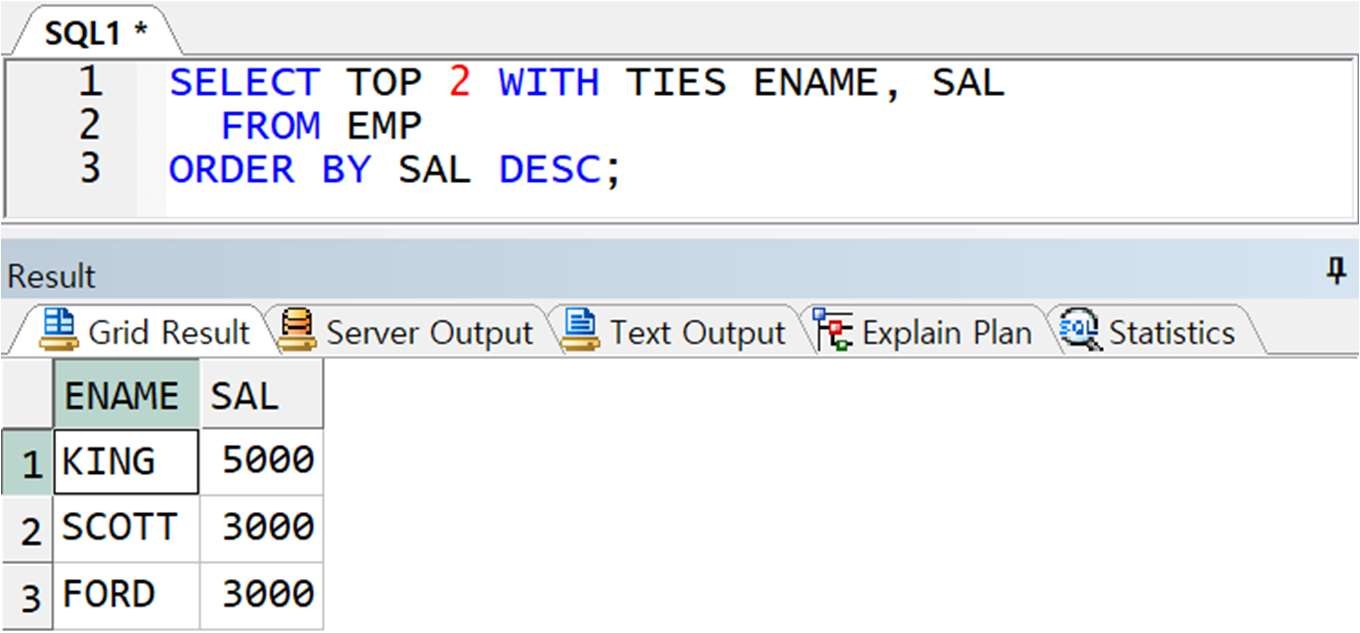
-> SAL 은 큰 순서대로 5000, 3000, 3000 이라 3000 이 공동 2 위이지만, TOP 2 는 2 개만 출력, WITH TIES 를 사용하면 동순위 행도 함께 출력 가능
14. 계층형 질의
● 계층형 질의
- 하나의 테이블 내 각 행끼리 관계를 가질 때, 연결고리를 통해 행과 행 사이의 계층(depth)을 표현하는 기법
ex) DEPT2 에서의 부서별 상하관계
- PRIOR 의 위치에 따라 연결하는 데이터가 달라짐
** 문법

** START WITH : 데이터를 출력할 시작 지정하는 조건
** CONNECT BY PRIOR : 행을 이어나갈 조건
** NOCYCLE : 순환이 발생하면 무한 루프가 될 수 있기 때문에 이를 방지하고자 사용
예제) DEPT2 테이블에 대해 각 부서의 레벨을 출력(최상위 부서가 1 레벨)
** 올바른 예
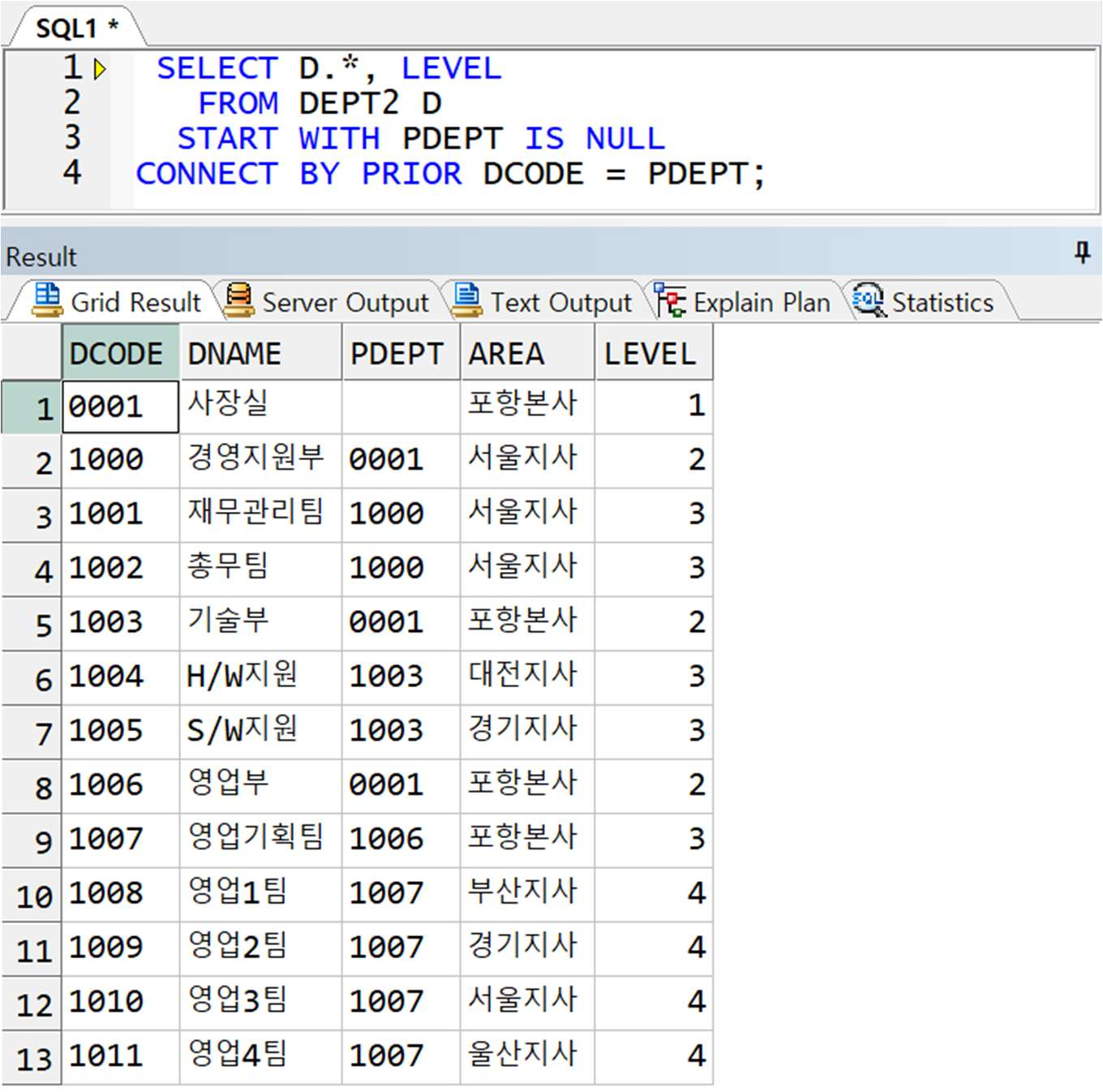
-> 사장실의 DCODE 를 넘겨 다시 각 행들의 PDEPT 와 비교해야 하므로 먼저 정해져야 하는 값의 방향에 PRIOR 전달!
** 잘못된 예
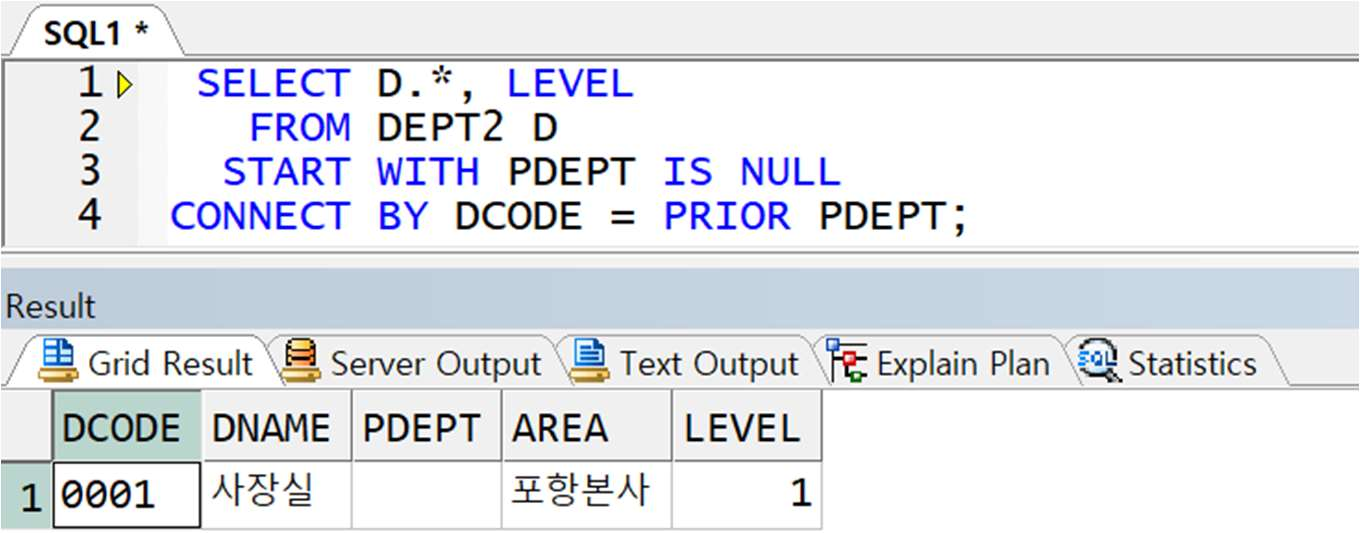
예제) 계층형 질의 조건 전달
CASE1) CONNECT BY 절에 전달 : 연결 조건이 추가되었으므로 모든 조건이 만족할 경우만 하위 레벨로 연결됨
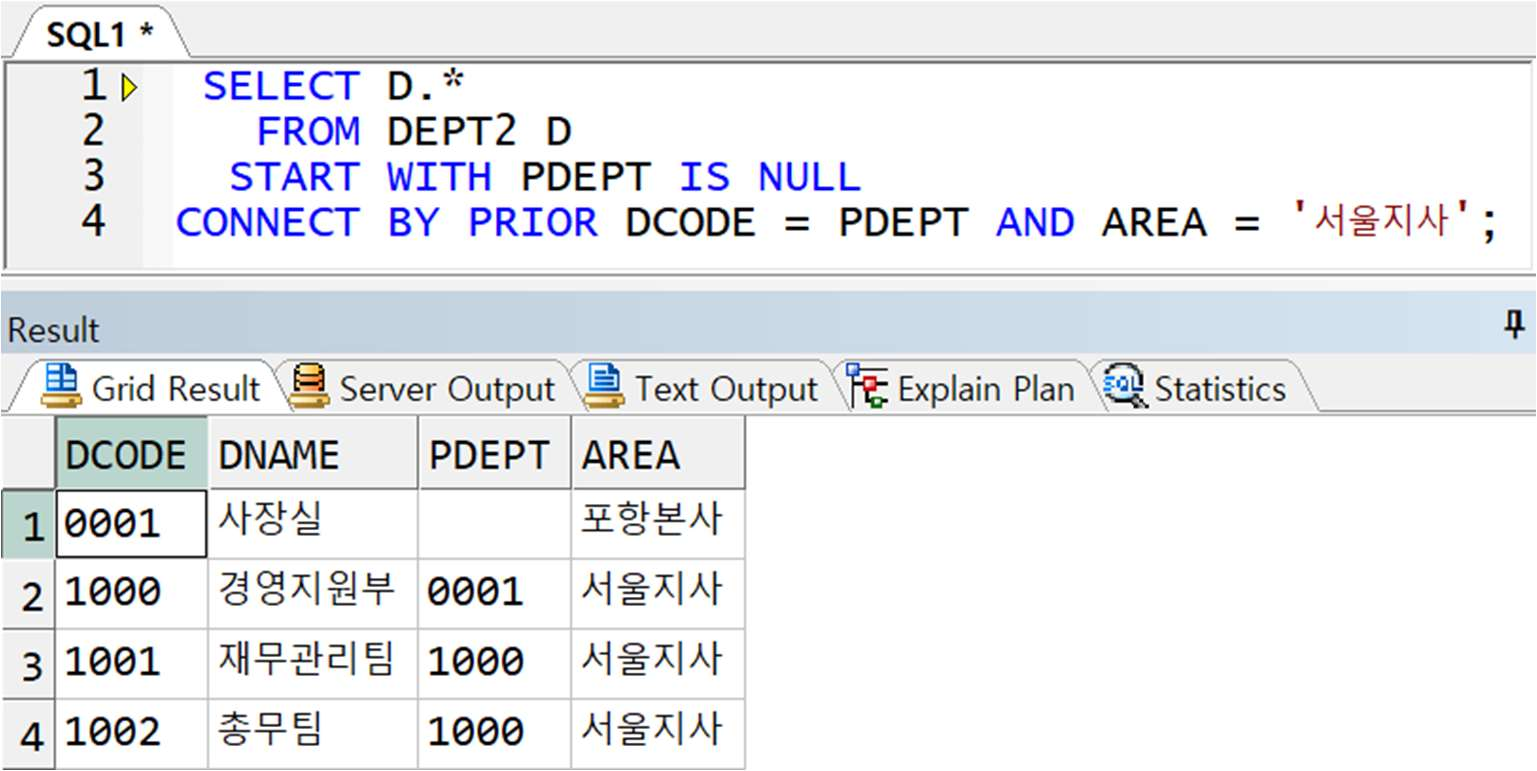
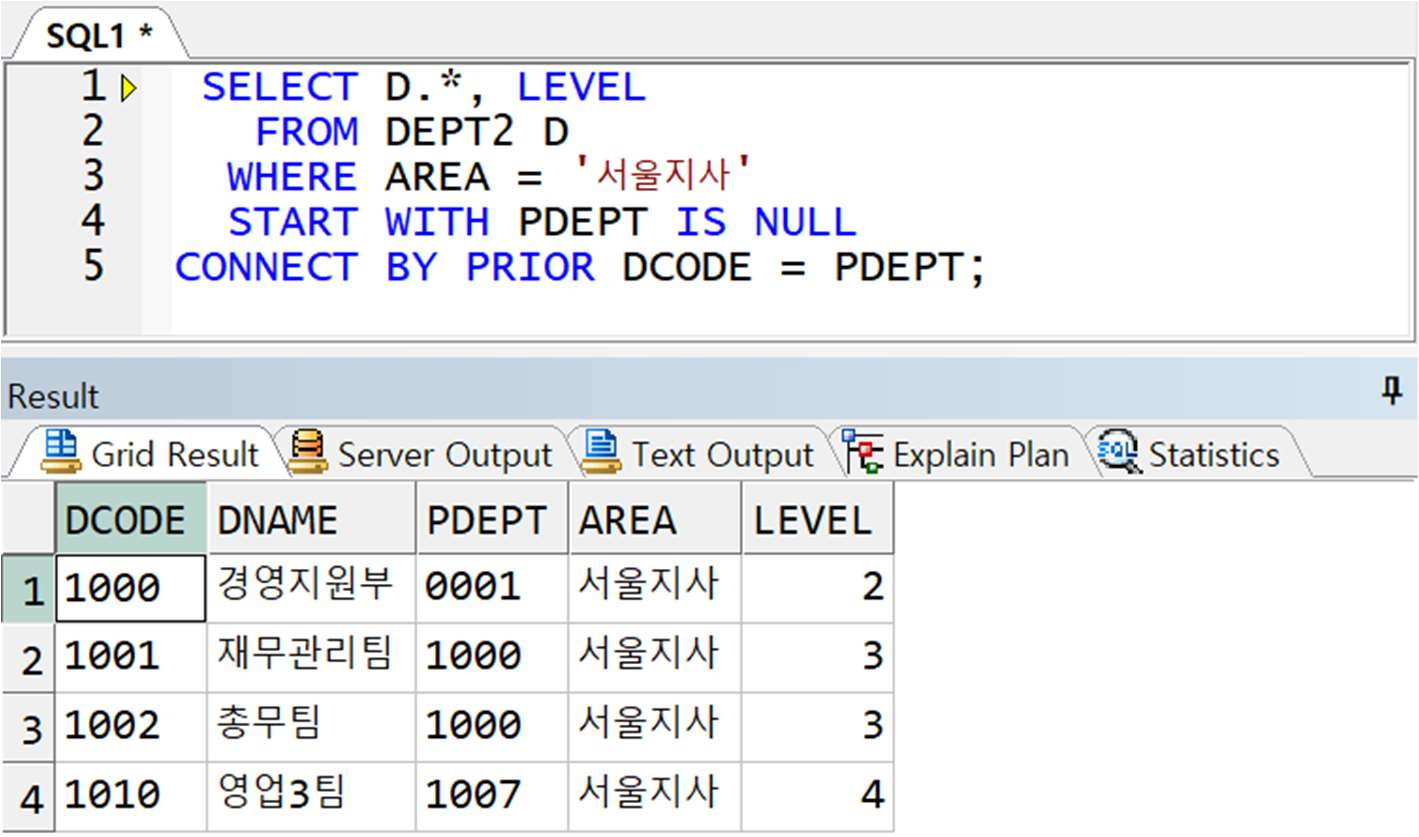
CASE2) WHERE 절에 전달 : 모든 출력 결과 중 ‘서울지사’ 데이터만 출력됨
※ 계층형 질의 가상 컬럼
1) LEVEL : 각 DEPTH 를 표현(시작점부터 1)
2) CONNECT_BY_ISLEAF : LEAF NODE(최하위노드) 여부(참:1, 거짓:0)
※ 계층형 질의 가상 함수
1) CONNECT_BY_ROOT 컬럼명 : 루트노드의 해당하는 컬럼값
2) SYS_CONNECT_BY_PATH(컬럼, 구분자) : 이어지는 경로 출력
3) ORDER SIBLINGS BY 컬럼 : 같은 LEVEL 일 경우 정렬 수행
4) CONNECT_BY_ISCYCLE : 계층형 쿼리의 결과에서 순환이 발생했는지 여부
예제) 계층형 질의절 가상 컬럼 및 함수의 사용
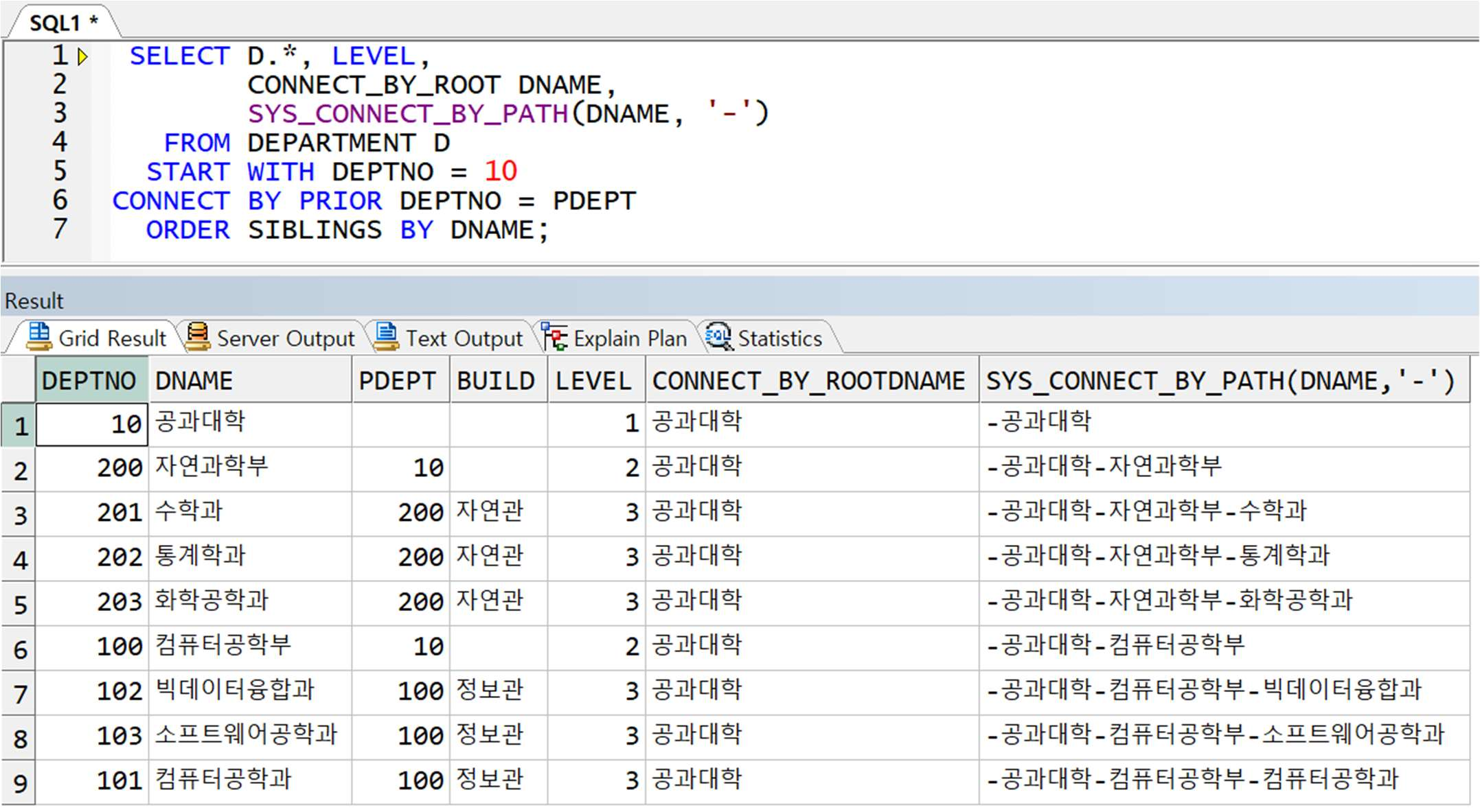
-> ORDER SIBLINGS BY 를 사용하여 같은 레벨일 경우 DNAME 오름차순으로 정렬, 2 레벨은 자연과학부 < 컴퓨터공학부 순서대로 출력되며, 자연과학부 내 3 레벨은 수학과 < 통계학과 < 화학공학과 순서대로 리턴되었음
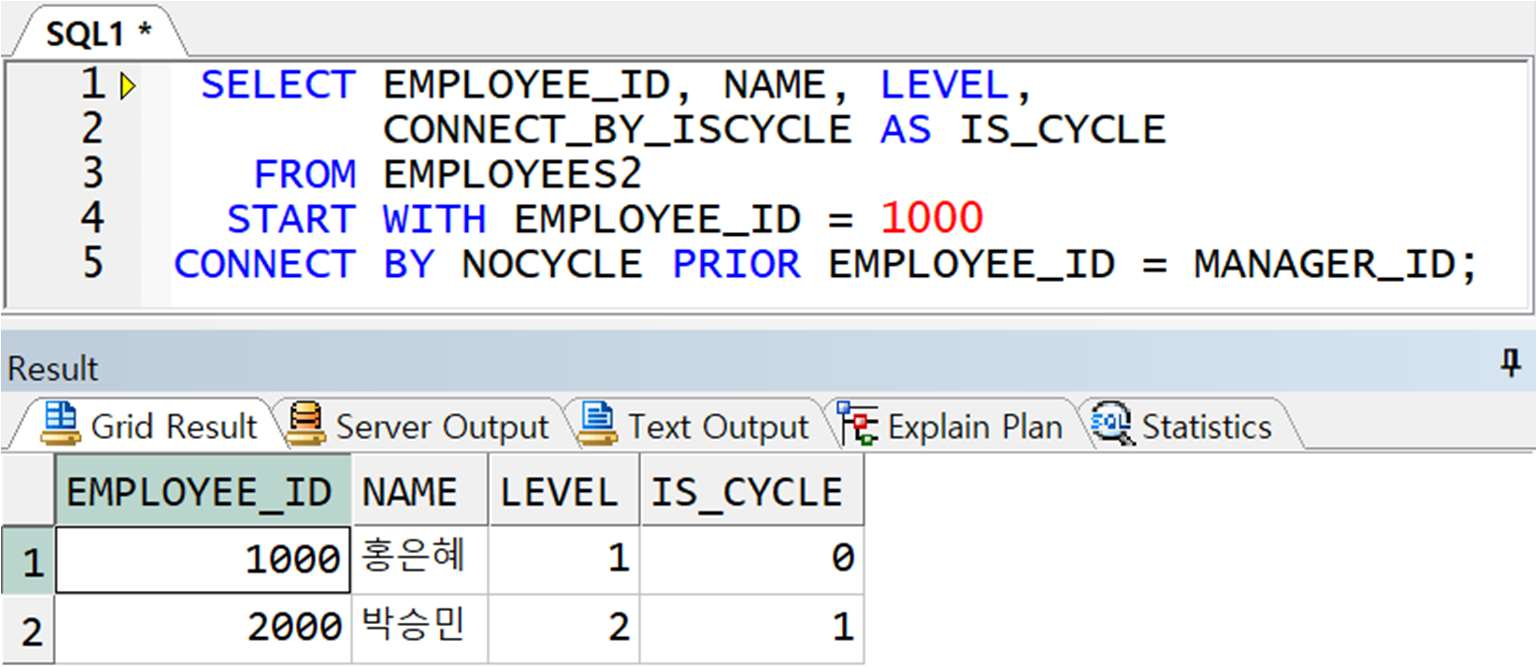
예제) NOCYCLE 옵션
< EMPLOYEES DATA >

< NOCYCLE 옵션 없이 – ERROR 발생 >
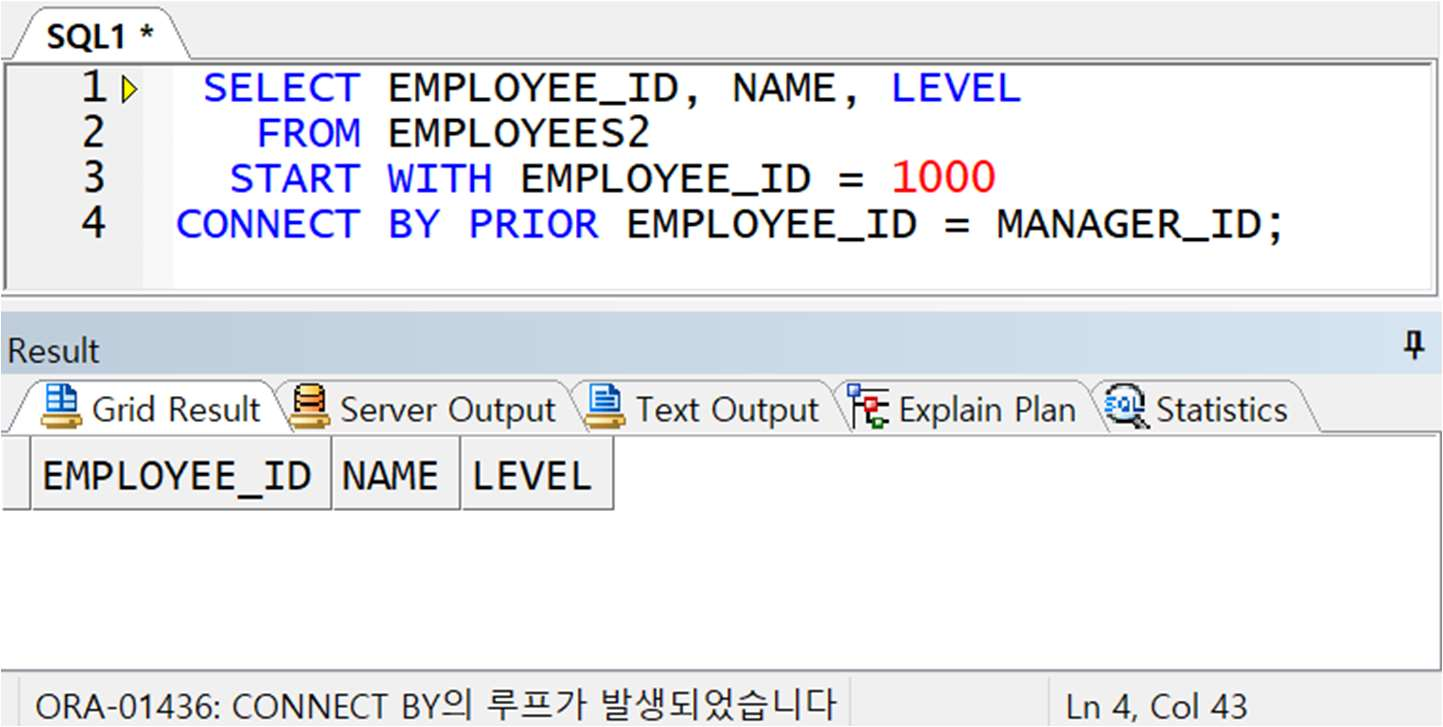
-> 1000 번 직원의 매니저는 2000 번 사원인데, 2000 번 사원도 1000 번 직원이 매니저이므로 서로 순환구조를 가짐 이런 관계에서 NOCYCLE 없이는 에러가 발생함
< NOCYCLE 옵션 수행 시 – 정상 출력 >
15. PIVOT 과 UNPIVOT
(데이터의 구조를 변경하는 기능)
● 데이터의 구조
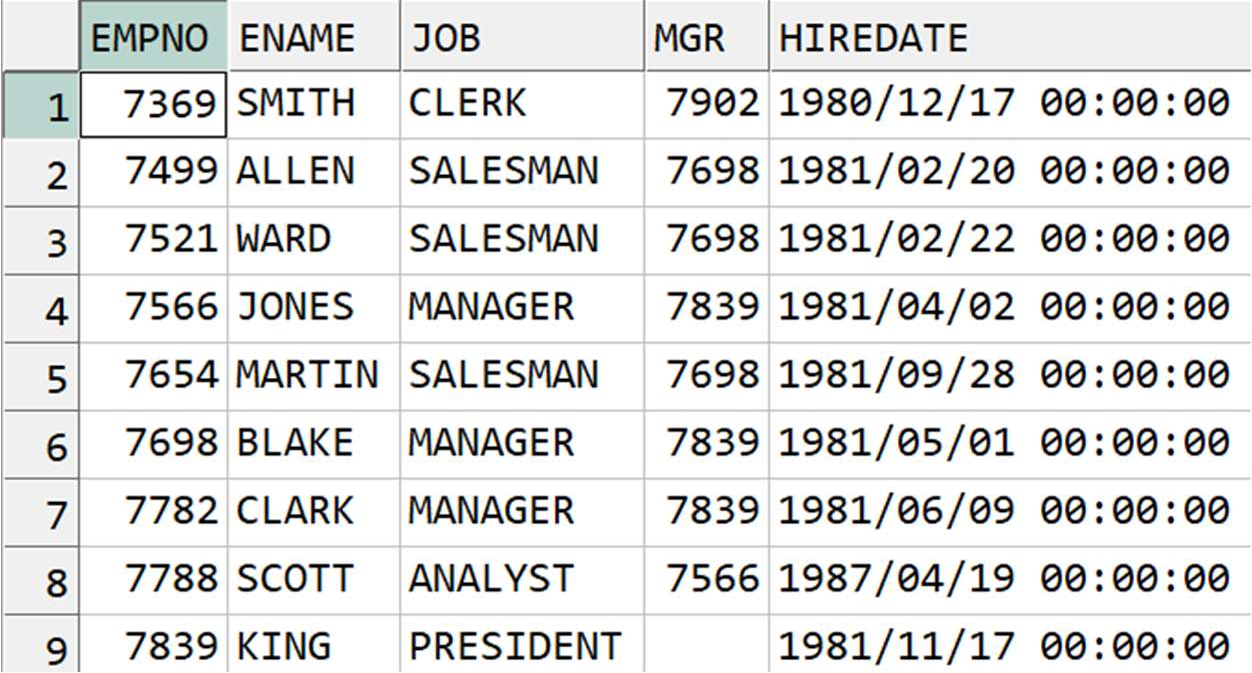
1) LONG DATA(Tidy data)
- 하나의 속성이 하나의 컬럼으로 정의되어 값들이 여러 행으로 쌓이는 구조
- RDBMS 의 테이블 설계 방식
- 다른 테이블과의 조인 연산이 가능한 구조
** LONG DATA
2) WIDE DATA(Cross table)
- 행과 컬럼에 유의미한 정보 전달을 목적으로 작성하는 교차표
- 하나의 속성값이 여러 컬럼으로 분리되어 표현
- RDBMS 에서 WIDE 형식으로 테이블 설계 시 값이 추가될 때 마다 컬럼이 추가돼야 하므로 비효율적!
- 다른 테이블과의 조인 연산이 불가함
- 주로 데이터를 요약할 목적으로 사용
** WIDE DATA
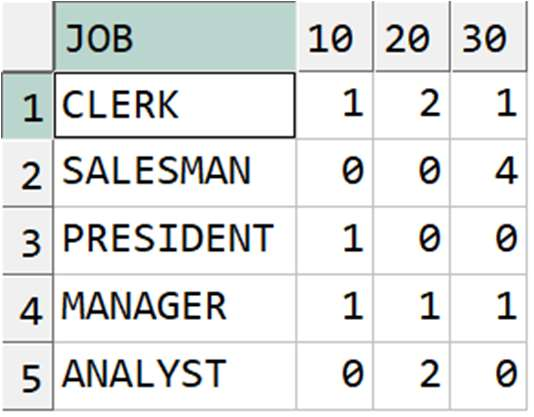
-> 컬럼의 정보는 부서번호로, 하나의 관찰대상(속성)을 한 컬럼으로 정의하지 않고 값의 종류별로 컬럼을 분리하였음
● 데이터 구조 변경
1) PIVOT : LONG -> WIDE
2) UNPIVOT : WIDE -> LONG
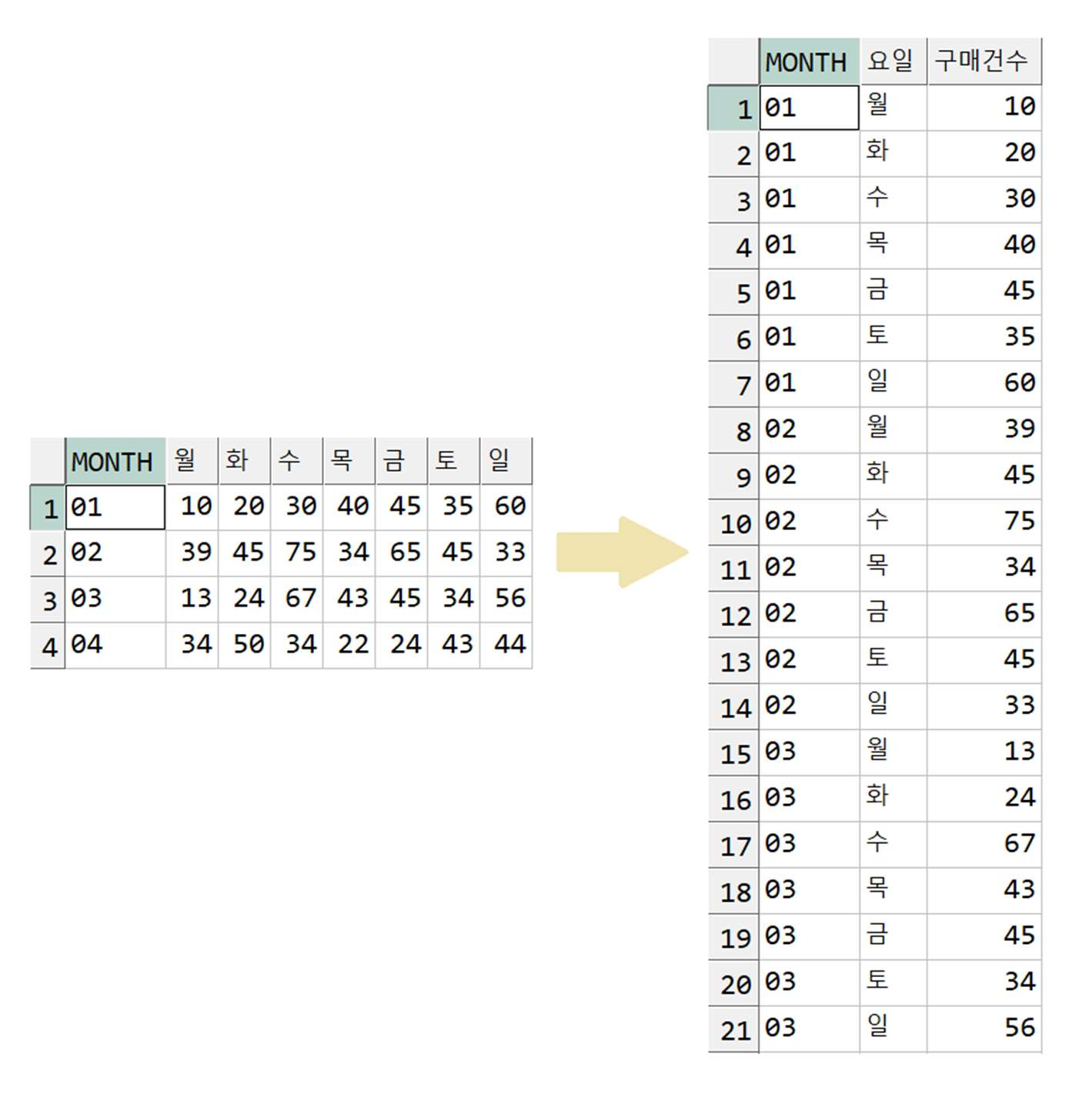
● PIVOT
- 교차표를 만드는 기능
- STACK 컬럼, UNSTACK 컬럼, VALUE 컬럼의 정의가 중요!
- FROM 절에 STACK, UNSTACK, VALUE 컬럼명만 정의 필요(필요 시 서브쿼리 사용하여 필요 컬럼 제한)
- PIVOT 절에 UNSTACK, VALUE 컬럼명 정의
- PIVOT 절 IN 연산자에 UNSTACK 컬럼 값을 정의
- FROM 절에 선언된 컬럼 중 PIVOT 절에서 선언한 VALUE 컬럼, UNSTACK 컬럼을 제외한 모든 컬럼은 STACK 컬럼이 됨
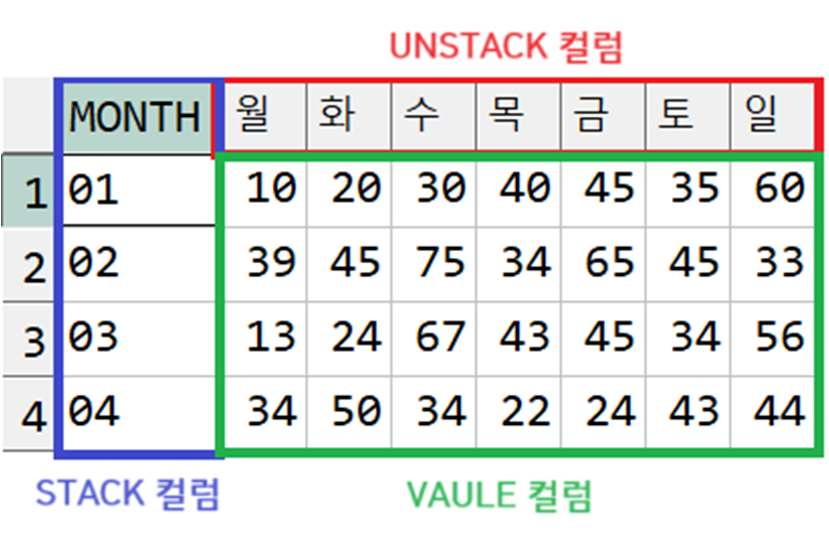
** 문법

※ 반드시 FROM 절에 STACK 컬럼, UNSTACK 컬럼, VALUE 컬럼 모두 명시!
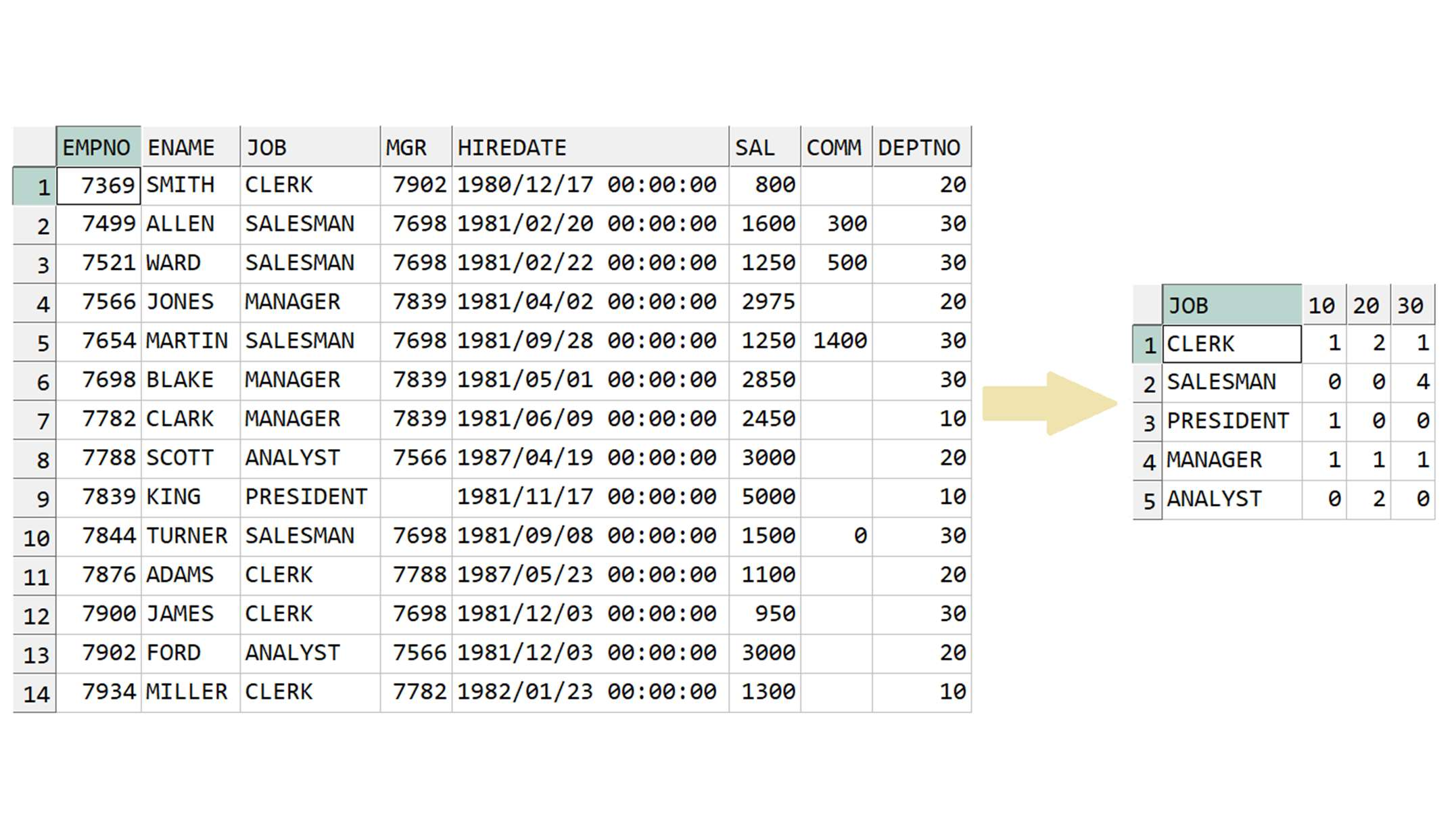
예제) EMP 테이블에서 아래와 같이 JOB 별 DEPTNO 별 도수(COUNT) 출력
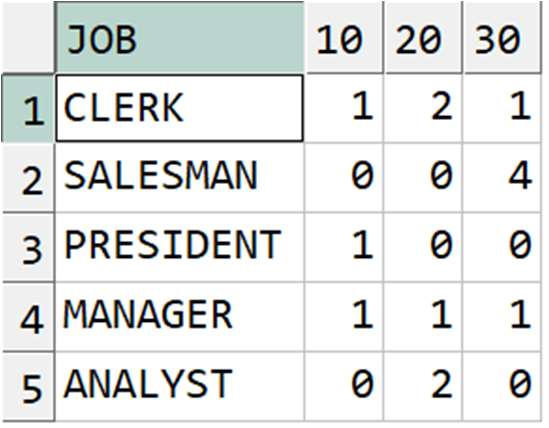
< 정답 >
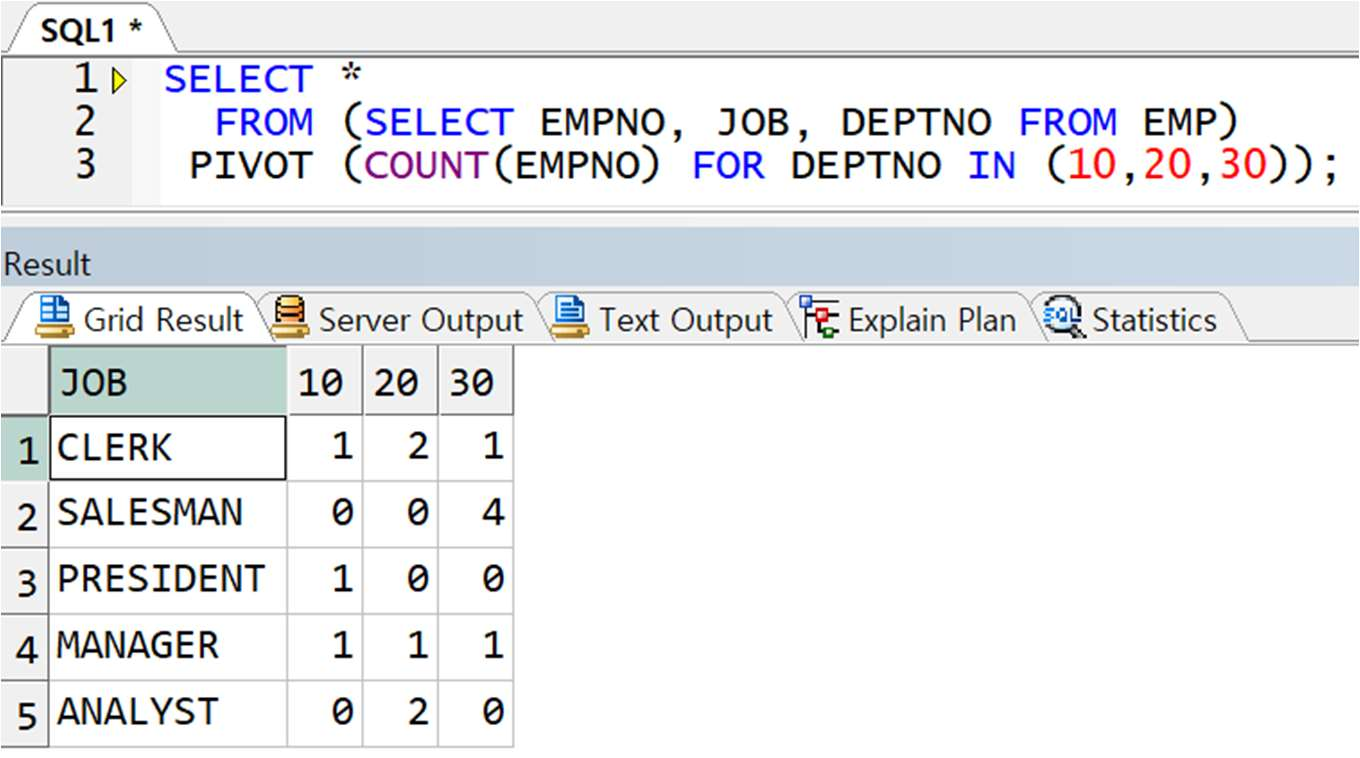
※주의 : 이 때 FROM 절 서브쿼리 안에 JOB 이 없으면 아래와 같이 그냥 부서별로의 도수가 출력됨
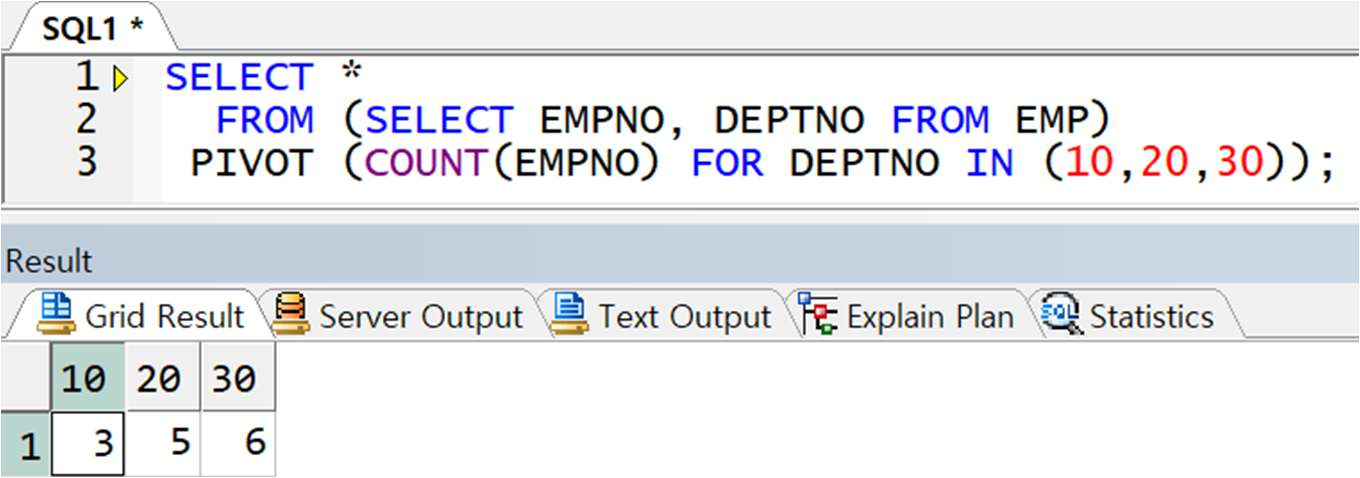
※주의 : FROM 절에 서브쿼리로 컬럼을 제한하지 않으면 STACK 컬럼이 많아짐!!
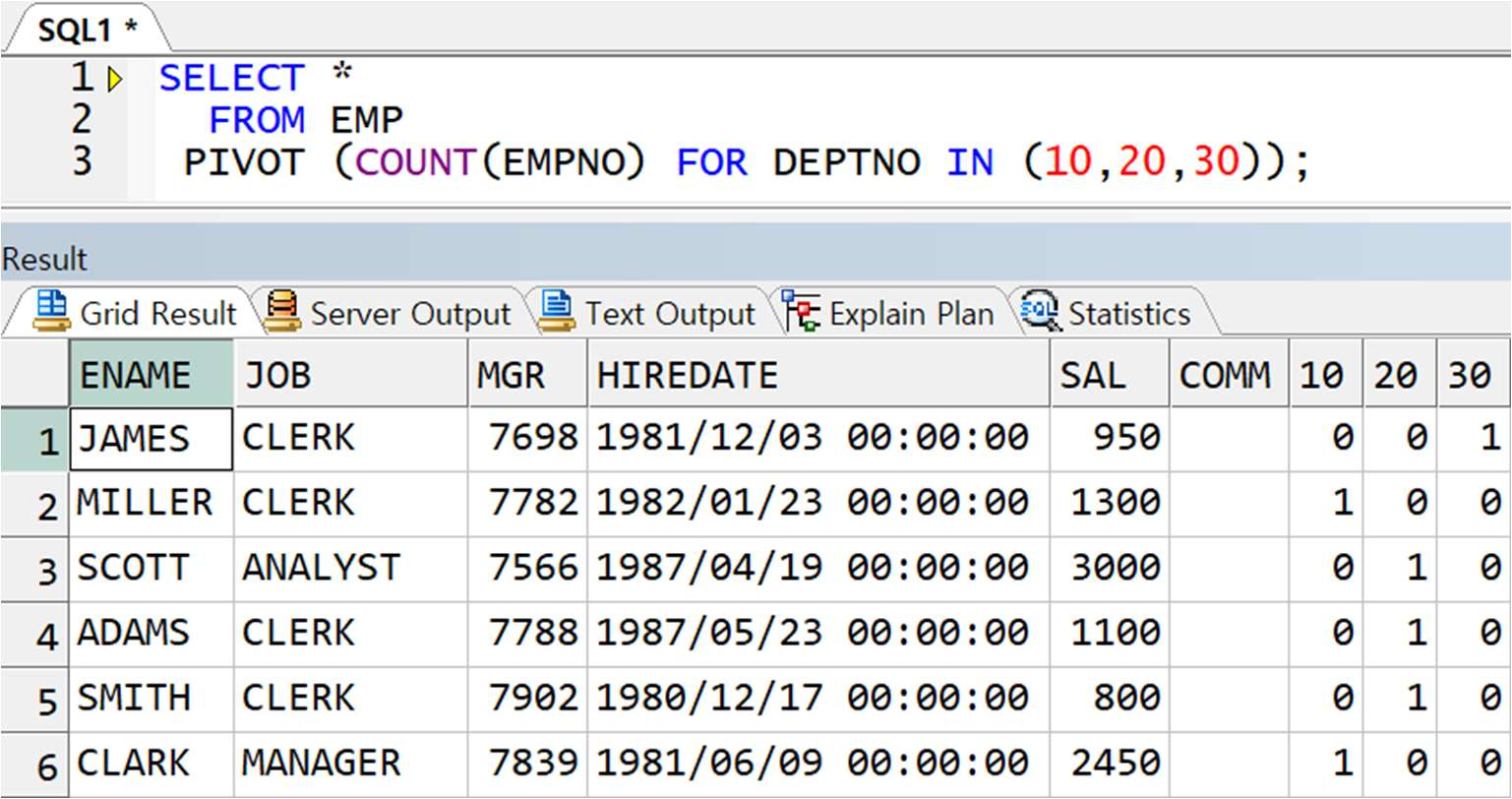
-> FROM 절에 서브쿼리로 필요한 컬럼만 정의하지 않으면 EMP 테이블의 모든 컬럼 중 PIVOT 절에 선언된 EMPNO, DEPTNO 컬럼을 제외한 모든 컬럼이 STACK 처리 됨
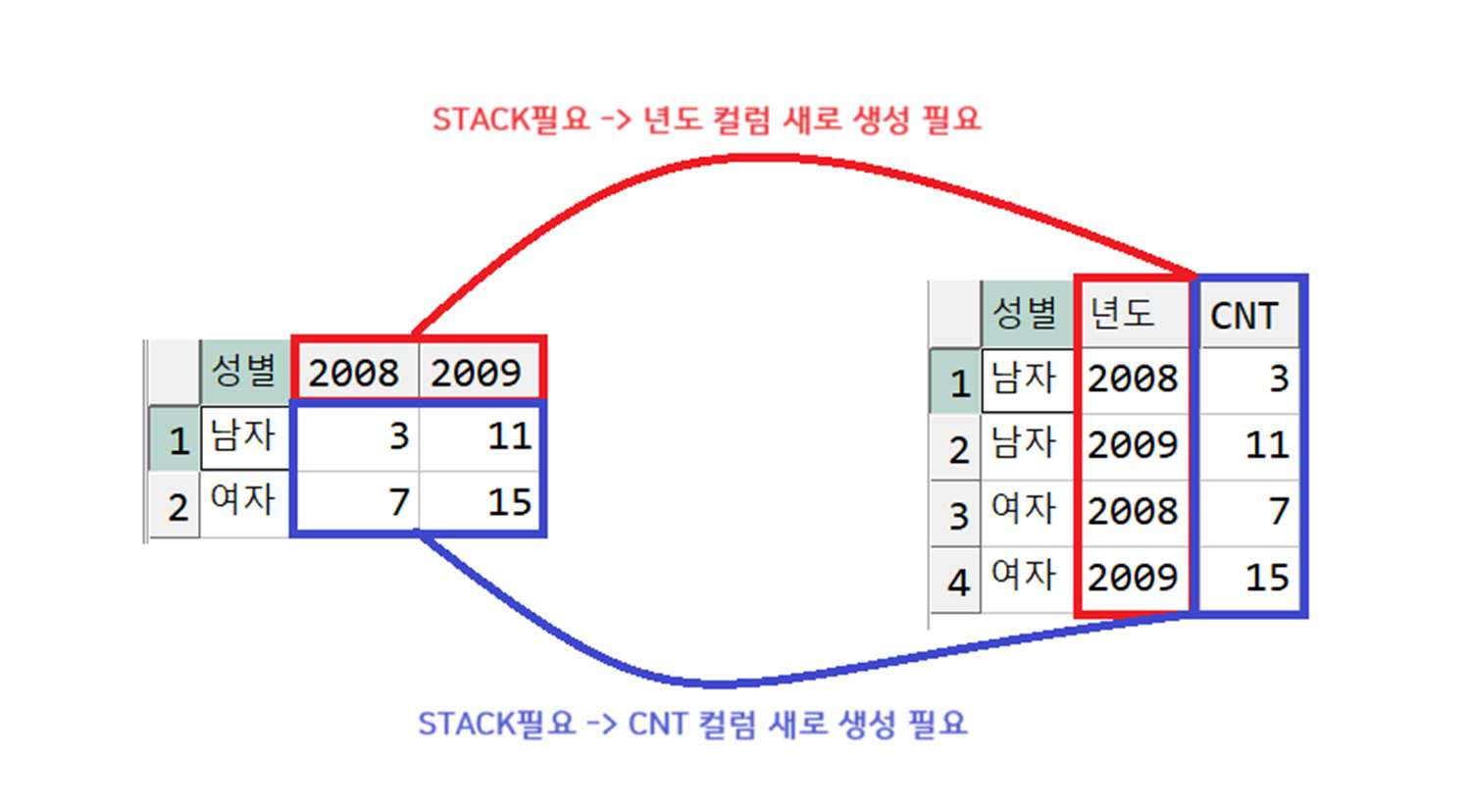
예제) 다음의 테이블에서 성별, 연도별 구매량 총 합을 표현하는 교차표 작성
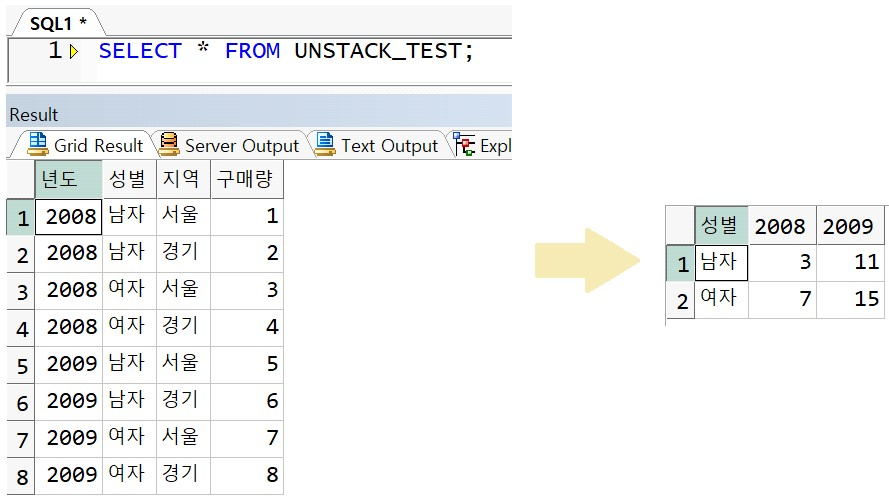
< 정답 >
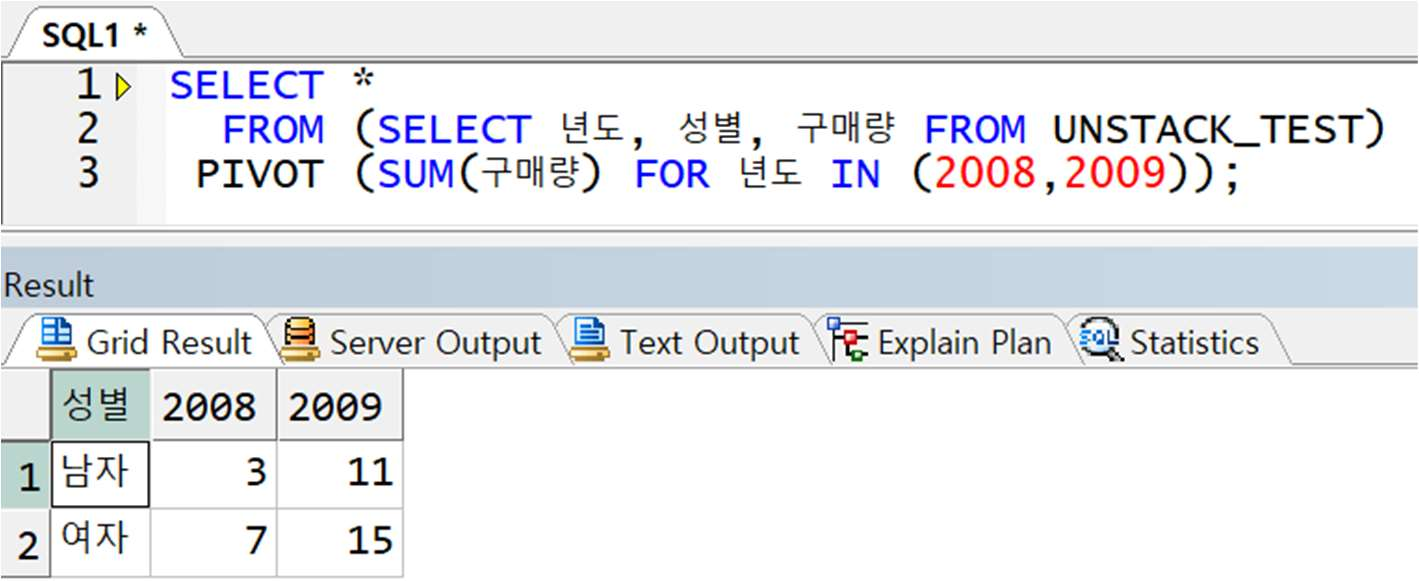
● UNPIVOT
- WIDE 데이터를 LONG 데이터로 변경하는 문법
- STACK 컬럼 : 이미 UNSTACK 되어 있는 여러 컬럼을 하나의 컬럼으로 STACK 시 새로 만들 컬럼이름
(사용자 정의)
- VALUE 컬럼 : 교차표에서 셀 자리(VALUE)값을 하나의 컬럼으로 표현하고자 할 때 새로 만들 컬럼명
(사용자 정의)
- 값 1, 값 2... : 실제 UNSTACK 되어 있는 컬럼이름들
** 문법

예제) 위 UNSTACK_TEST PIVOT 결과가 STACK_TEST 테이블에 저장되어 있을 때, 다시 STACK_TEST 테이블의 값을 UNSTACK_TEST 형태로 변경(STACK 처리)
< 정답 >
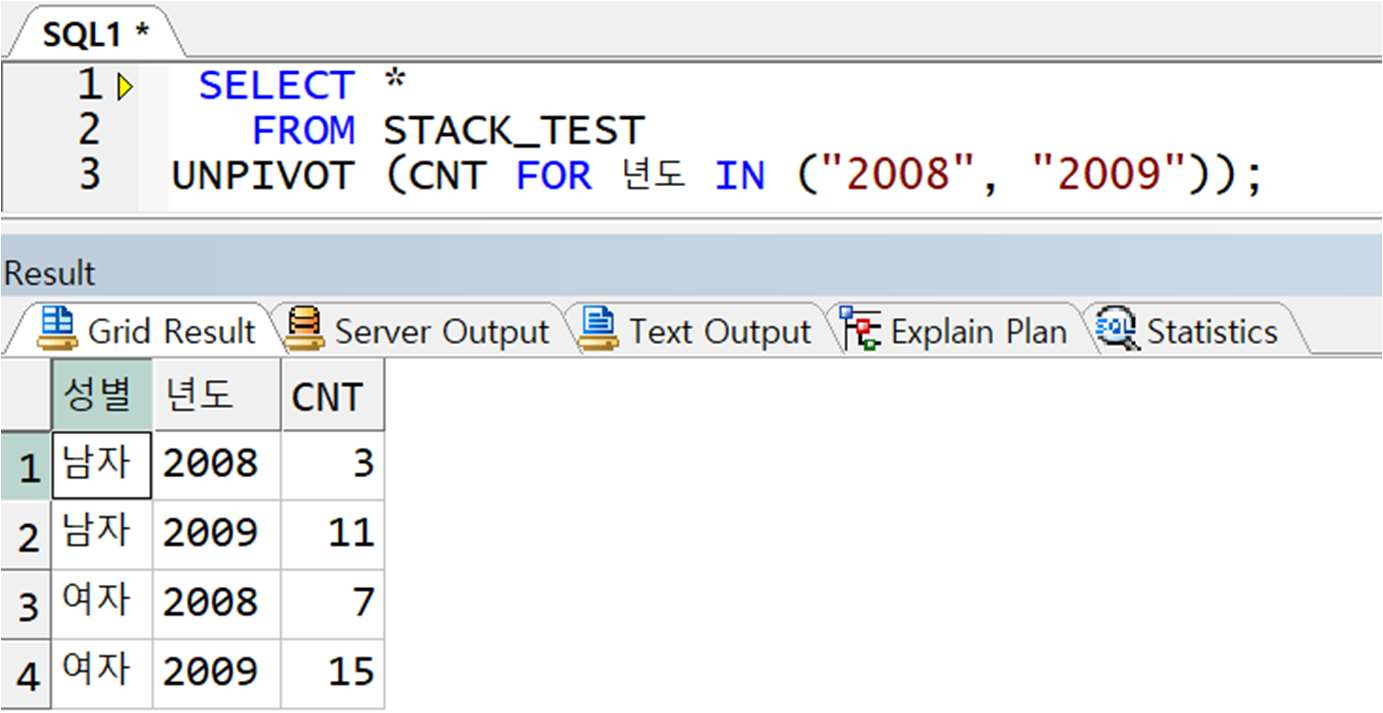
-> IN 뒤에 값은 UNSTACK 데이터의 컬럼명이 숫자이지만 컬럼명은 문자로 저장되므로 쌍따옴표 전달 필요!
예제) 아래 테이블 STACK 처리(LONG DATA 로 변환)
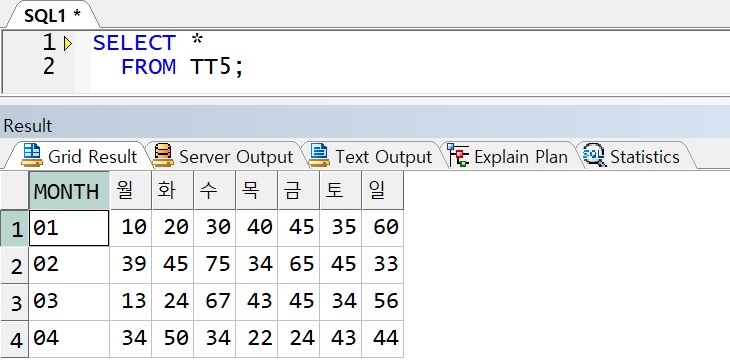
< 정답 >
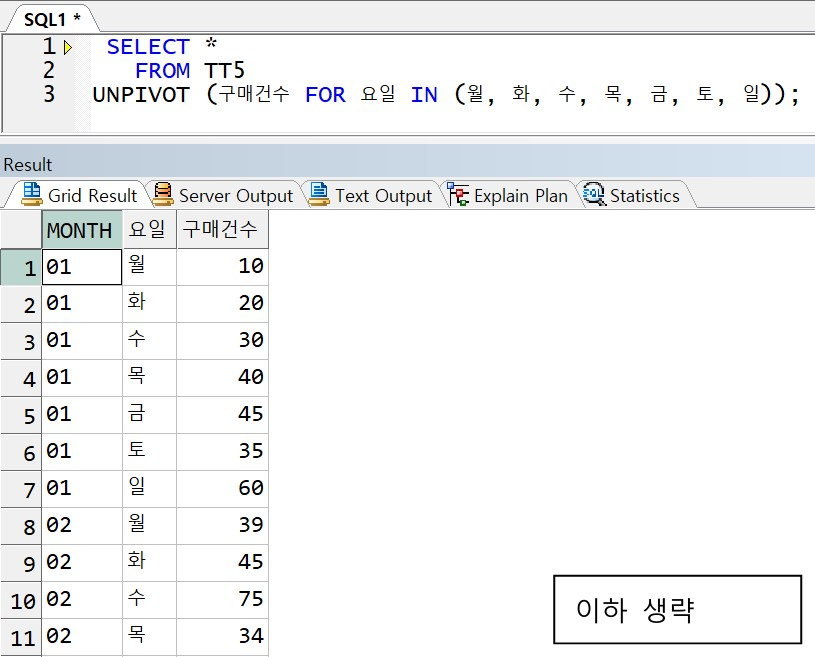
-> 월 , 화, 수, 목, .... 값들은 컬럼명이므로 컬럼명과 테이블명처럼 대명사(객체이름)는 쌍따옴표를 붙이지 않음 주의!
16. 정규 표현식
● 정규 표현식
- 문자열의 공통된 규칙을 보다 일반화 하여 표현하는 방법
- 정규 표현식 사용 가능한 문자함수 제공(regexp_replace, regexp_substr, regexp_instr, ....)
ex) 숫자를 포함하는, 숫자로 시작하는 4 자리, 두번째 자리가 A 인 5 글자
예제) 일반화 규칙 찾아내기
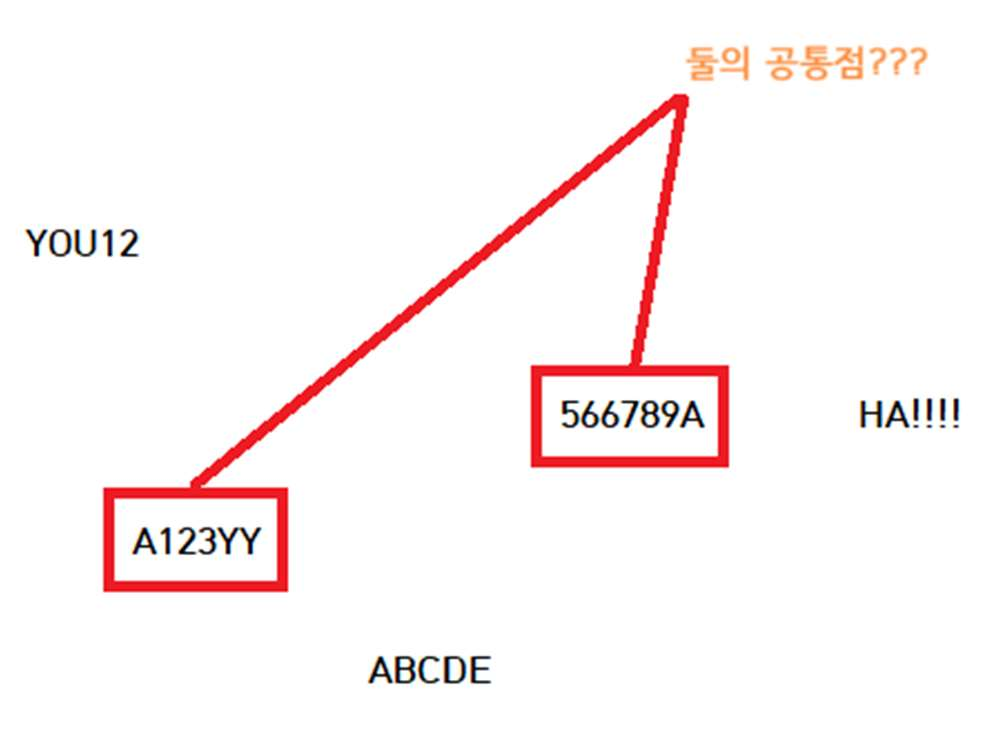
-> "숫자를 연속적으로 3 개이상 포함하는"이 공통 패턴임
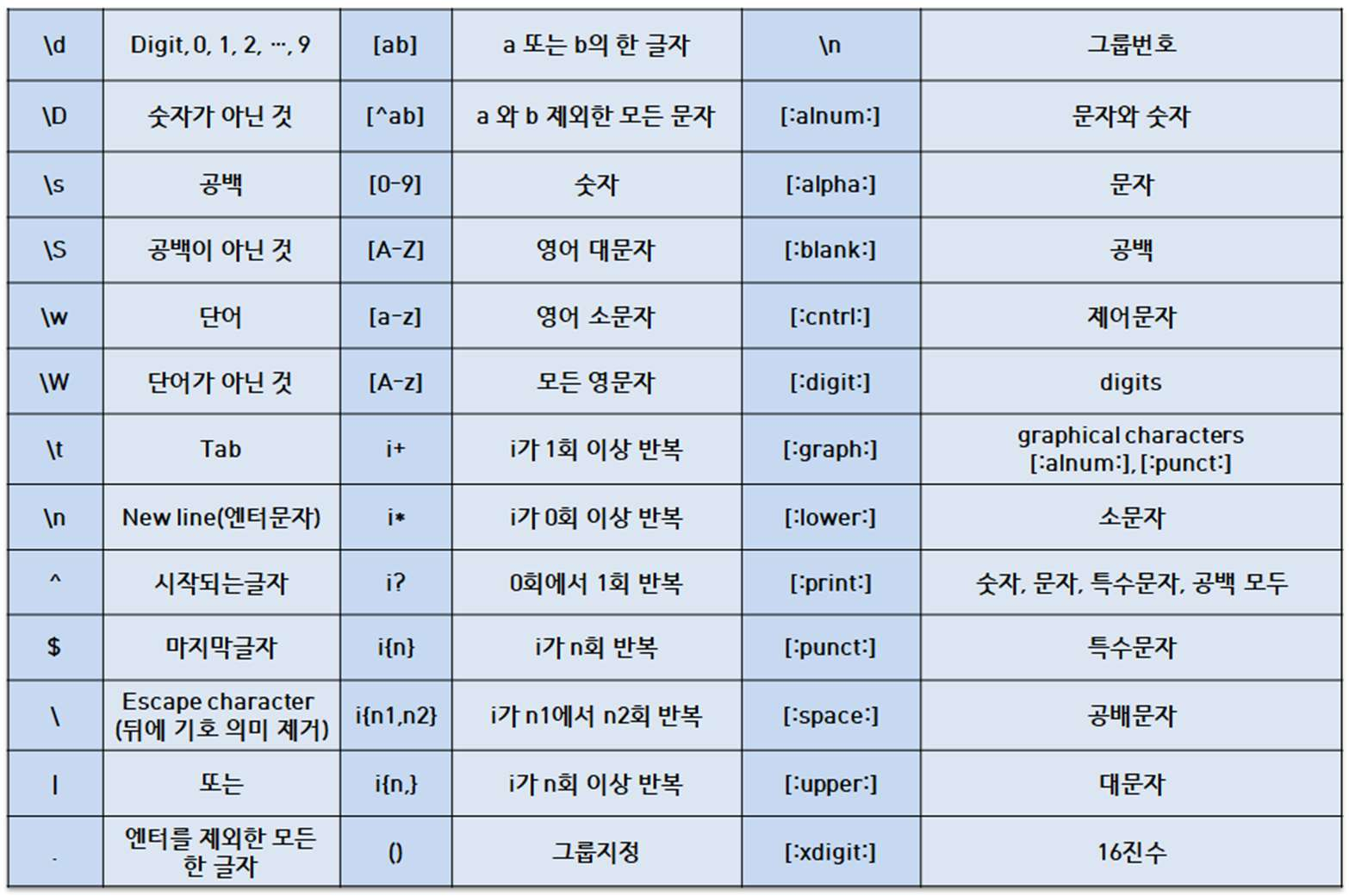
* 정규 표현식 종류
예제) 전화번호의 일반화

-> 전화번호는 숫자와 -으로 구성 -> [0-9-]+ 로 표현 가능([] 안에 들어가는 패턴이 한자리의 문자열을 구성할 수 있는 값들)
-> 두 전화번호가 tel 값은 동시에 있지만, )가 있는 경우와 없는 경우를 모두 표현 -> ?사용(?는 값이 없거나 1 개 있음을 의미)
● REGEXP_REPLACE
- 정규식 표현을 사용한 문자열 치환 가능
** 문법
(대상, 찾을문자열, [바꿀문자열], [검색위치], [발견횟수], [옵션])
1. 특징
- 바꿀문자열 생략 시 문자열 삭제
- 검색위치 생략 시 1
- 발견횟수 생략 시 0(모든)
2. 옵션
- c : 대소를 구분하여 검색
- i : 대소를 구분하지 않고 검색
- m : 패턴을 다중라인으로 선언 가능
예제) ID 에서 숫자 삭제
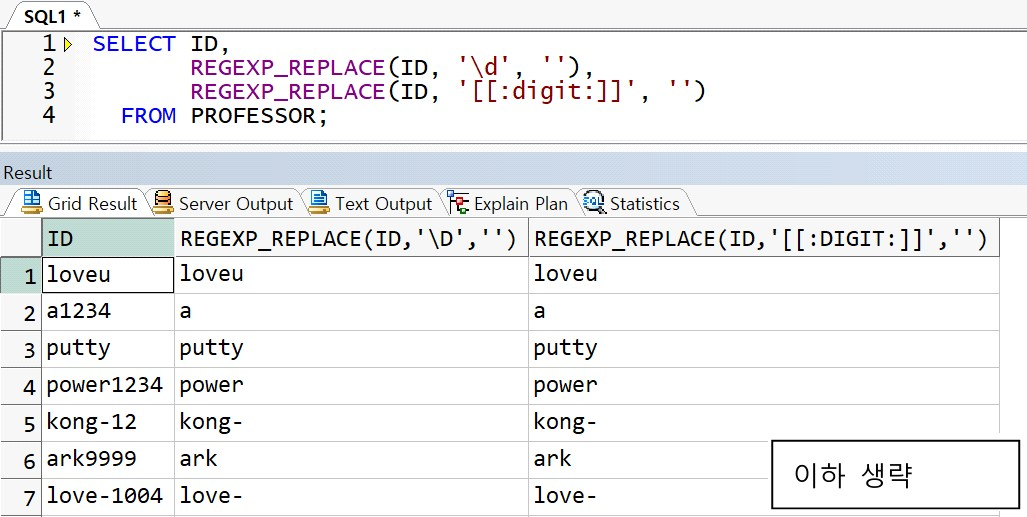
-> 빈문자열을 전달하여 숫자를 모두 삭제 처리
예제) ID 에서 특수기호 삭제
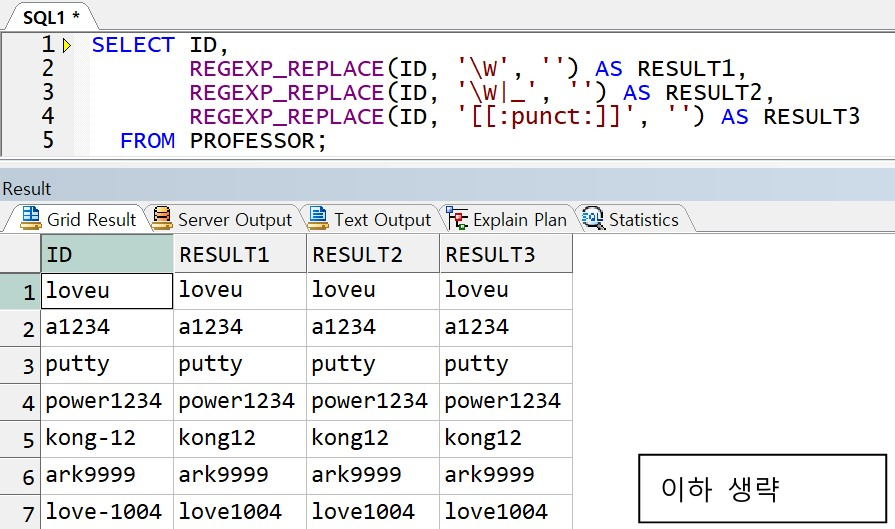
-> \w 는 문자와 숫자, _를 포함, \W 는 \w 의 반대 집합이므로 문자와 숫자와 _가 아닌 특수기호와 공백을 의미
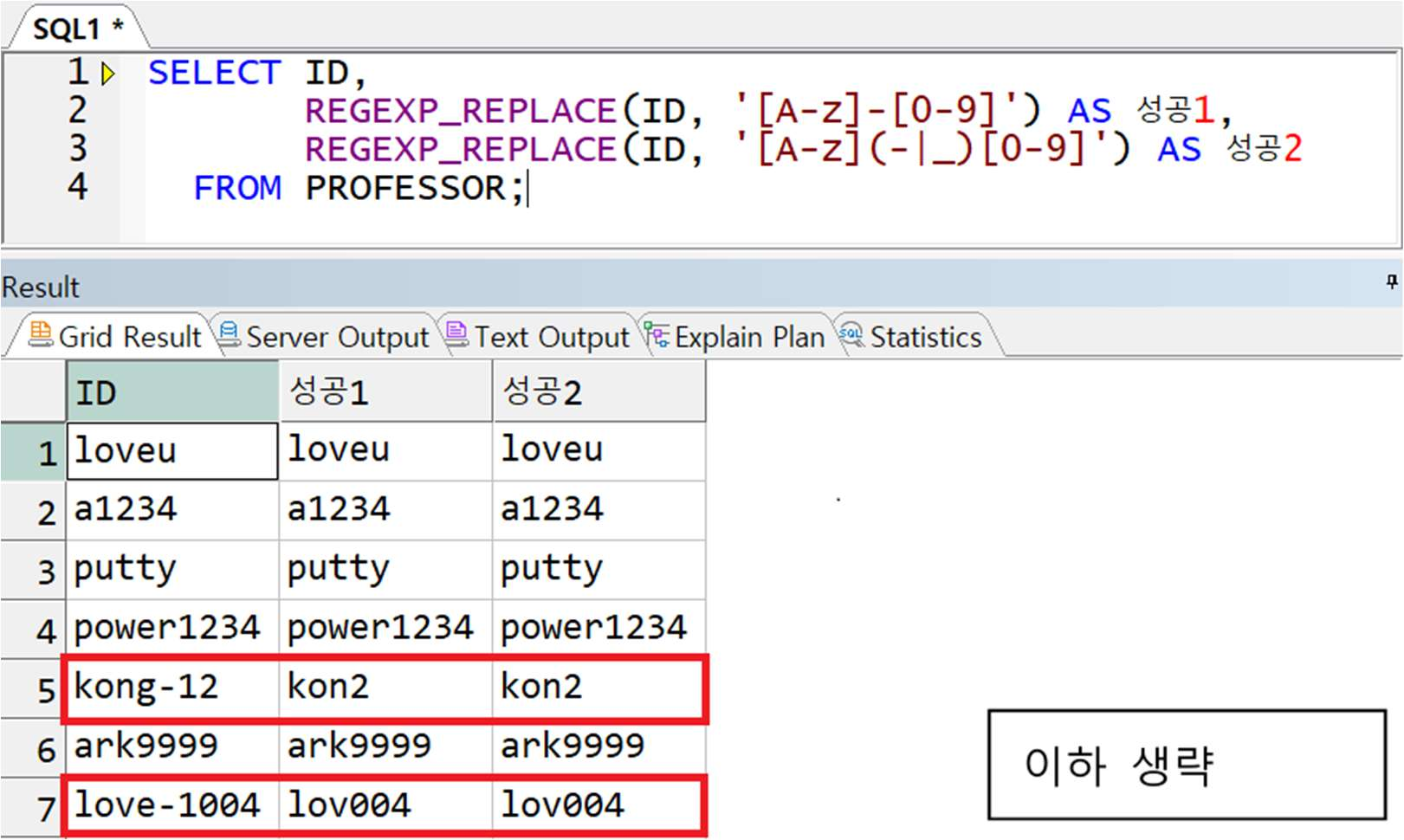
예제) PROFESSOR 테이블의 ID 에서 문자와 문자 바로 뒤에 오는 숫자를 삭제(대소구분 X)
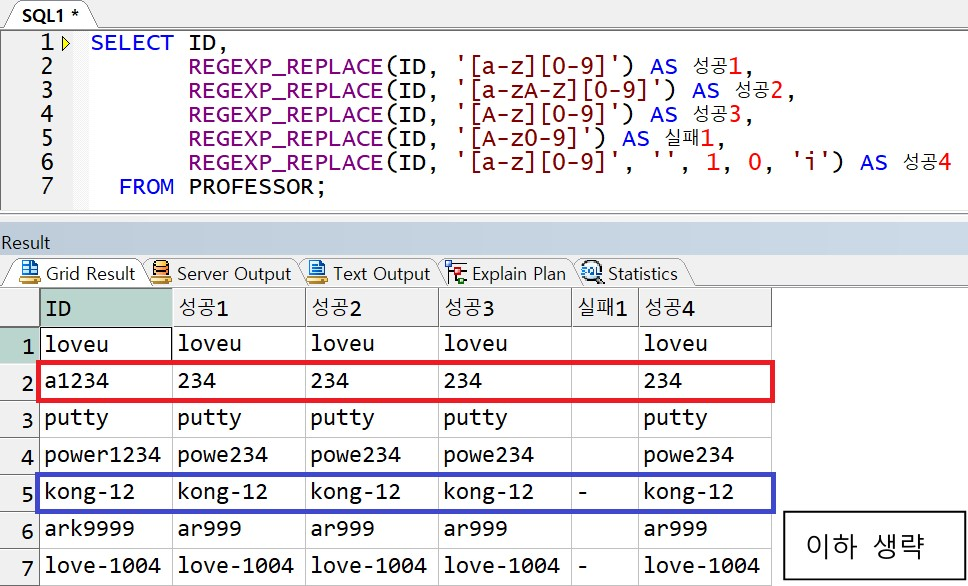
** kong-12 에서 g-1 을 지우는 방법
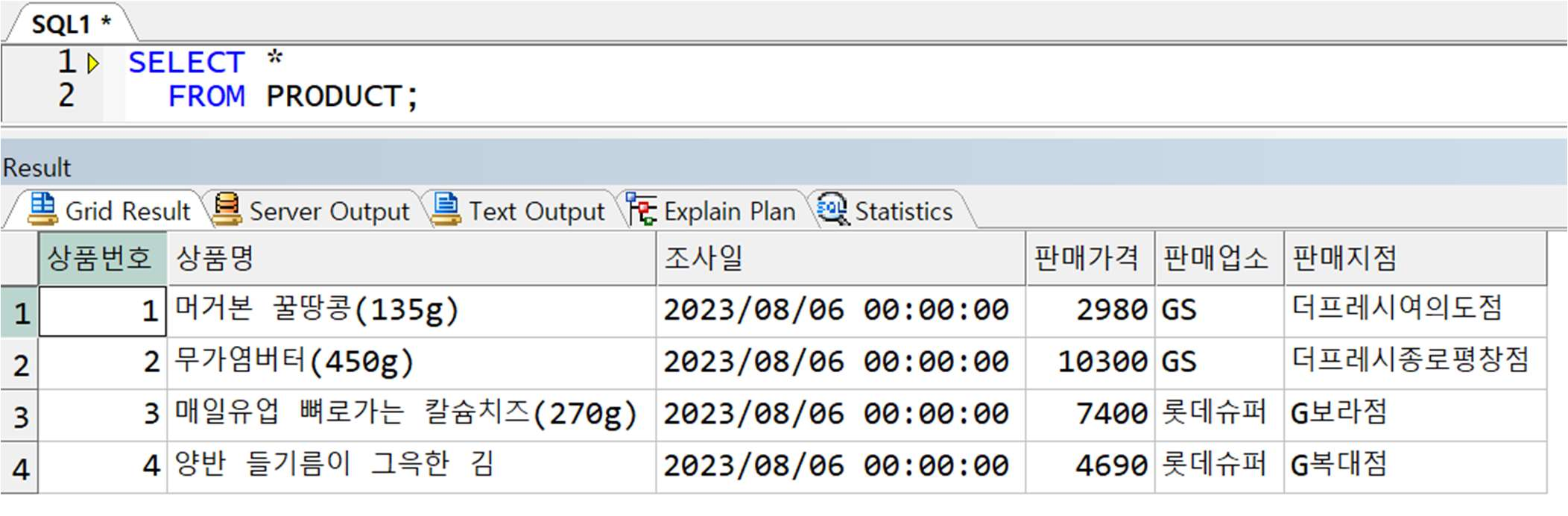
예제) PRODUCT 테이블의 상품명에서 괄호포함, 괄호안에 들어가는 모든 글자를 삭제
** 테이블 데이터
** 정답
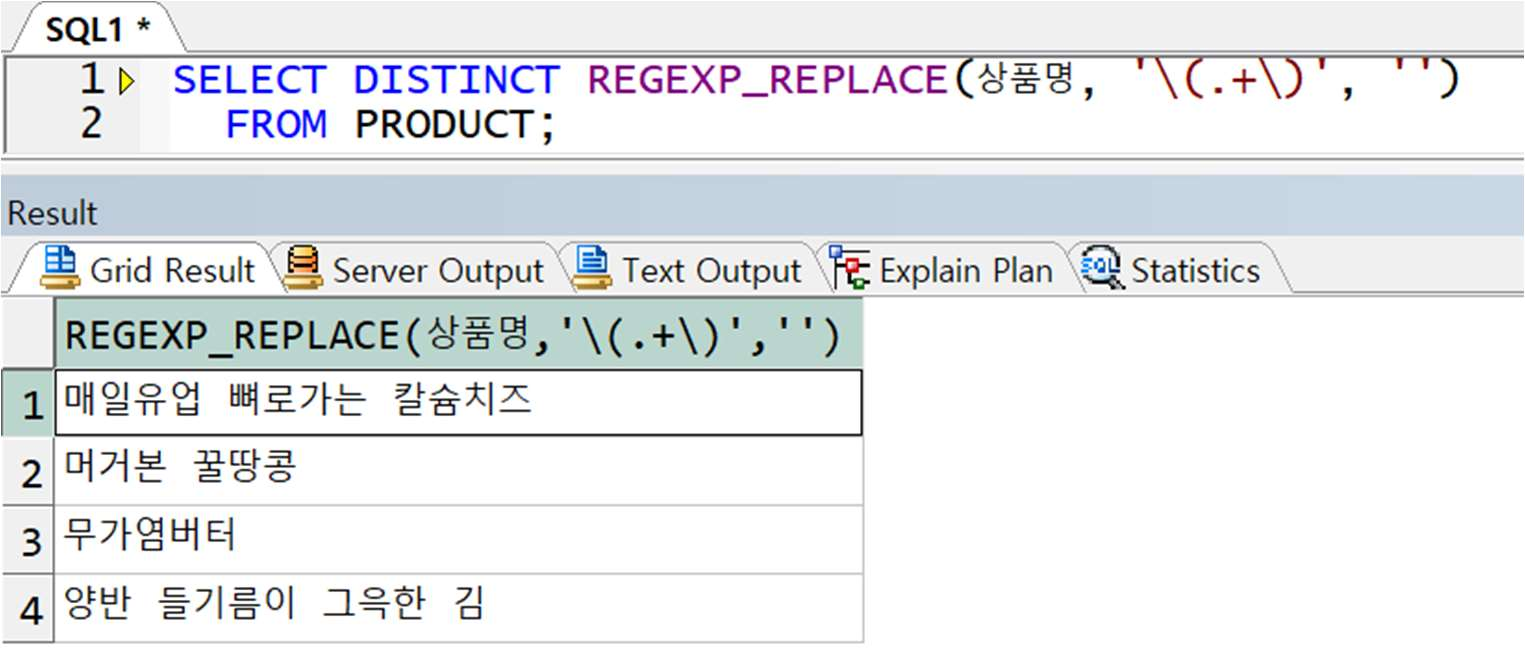
-> 괄호는 서브그룹을 만드는 정규 표현식이므로 일반 괄호를 표현하기 위해서는 \) 로 전달해야 함
-> \(.+\) : ()안에 엔터를 제외한 모든 값 허용
예제) REGEXP_REPLACE 를 사용하여 두 번째 발견된 문자 값을 X 로 치환
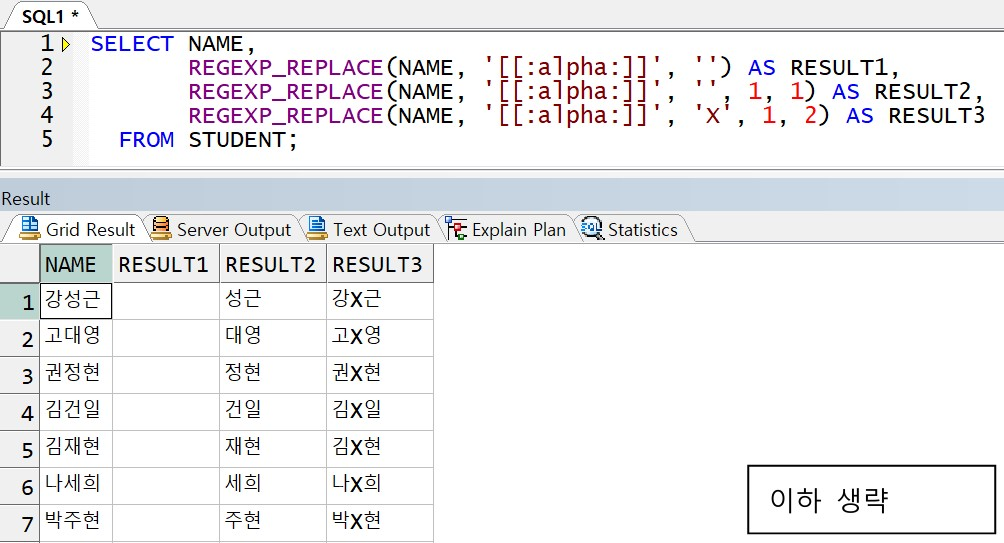
-> 문자 삭제 시 원하는 찾고자 하는 시작 위치와 발견횟수를 전달 할 수 있음
-> RESULT3 : 처음부터 스캔하여 두 번째로 발견되는 문자를 X 로 치환(마스킹 처리)
● REGEXP_SUBSTR
- 정규식 표현식을 사용한 문자열 추출
- 옵션은 REGEXP_SUBSTR 과 동일
** 문법
REGEXP_SUBSTR(대상, 패턴, [검색위치], [발견횟수], [옵션], [추출그룹])
** 특징
- 검색위치 생략 시 1
- 발견횟수 생략 시 1
- 추출그룹은 서브패턴을 추출 시 그 중 추출할 서브패턴 번호
예제) 전화번호를 분리하여 지역번호 추출
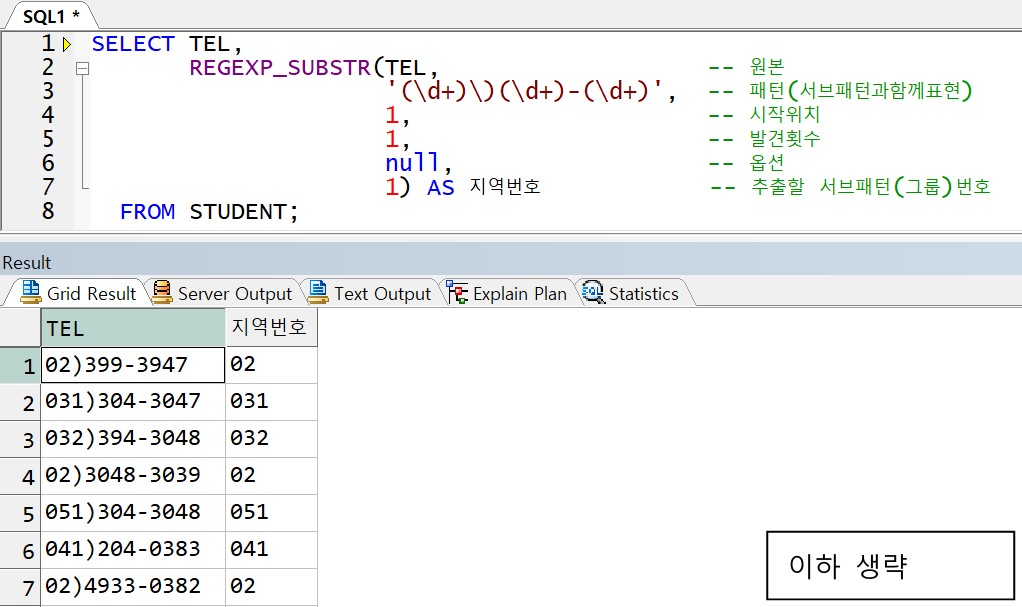
-> 전화번호 구성 : 숫자여러개 + ) + 숫자여러개 + - + 숫자여러개 차례대로 \d+, \), \d+, -, \d+ 로 표현 가능, 그 중 첫 번째 그룹을 추출
예제) 이메일 아이디 추출(서브패턴 활용)
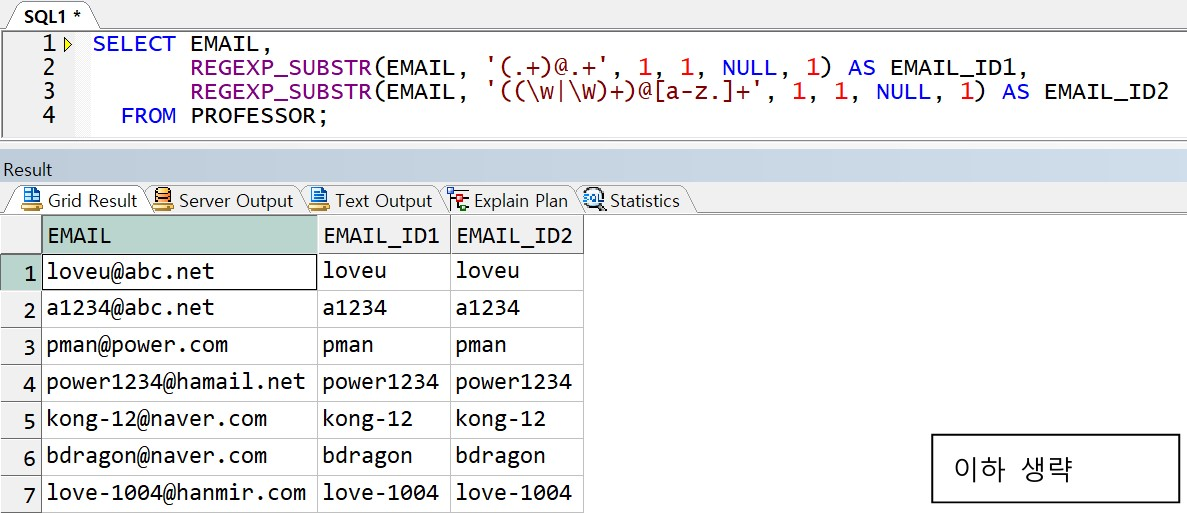
-> EMAIL 주소는 EMAIL_ID@ENGINE 으로 구성
-> EMAIL_ID : 몇 특수기호를 제외한 영문, 숫자, 기호로 구성
-> ENGINE : 영문과 .으로 구성
3. REGEXP_INSTR
- 주어진 문자열에서 특정패턴의 시작 위치를 반환
** 문법
REGEXP_INSTR(원본, 찾을문자열, [시작위치], [발견횟수])
** 특징
- 시작위치 생략 시 처음부터 확인(기본값:1)
- 발견횟수 생략 시 처음 발견된 문자열 위치 리턴
예제) ID 값에서 두 번째 발견된 숫자의 위치
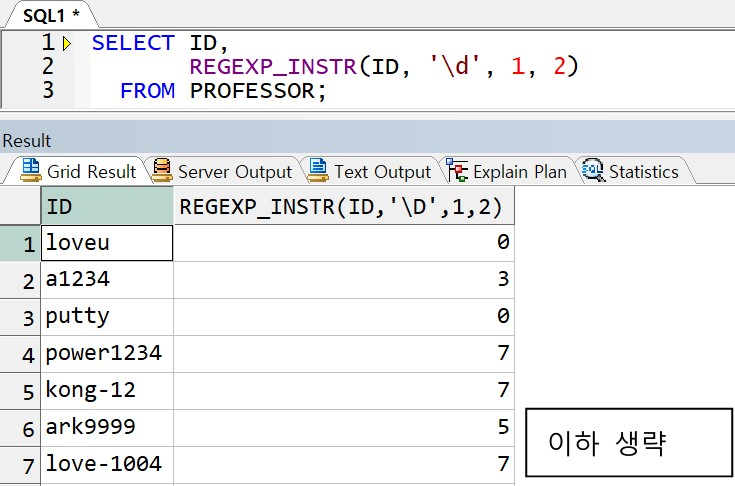
-> \d 는 숫자를 나타내는 표현이고, 뒤에 횟수를 지정하지 않으면 한 자리수의 숫자를 의미함
예제) 정규식 표현식을 사용한 패턴에 일치하는 n 번째 문자열 위치
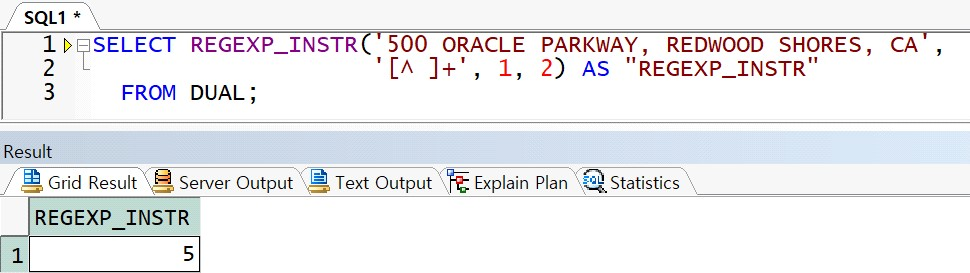
-> 다음과 같은 문자열에서 공백이 아닌 문자열의 반복들 중 처음부터 스캔하여 두 번째 발견된 것의 위치 리턴
● REGEXP_LIKE
- 주어진 문자열에서 특정패턴을 갖는 경우 반환(WHERE 절 사용만 가능)
- 옵션 REGEXP_REPLACE 와 동일
** 문법
REGEXP_LIKE(원본, 찾을문자열, [옵션])
예제) ID 값이 숫자로 끝나는 교수 정보 출력
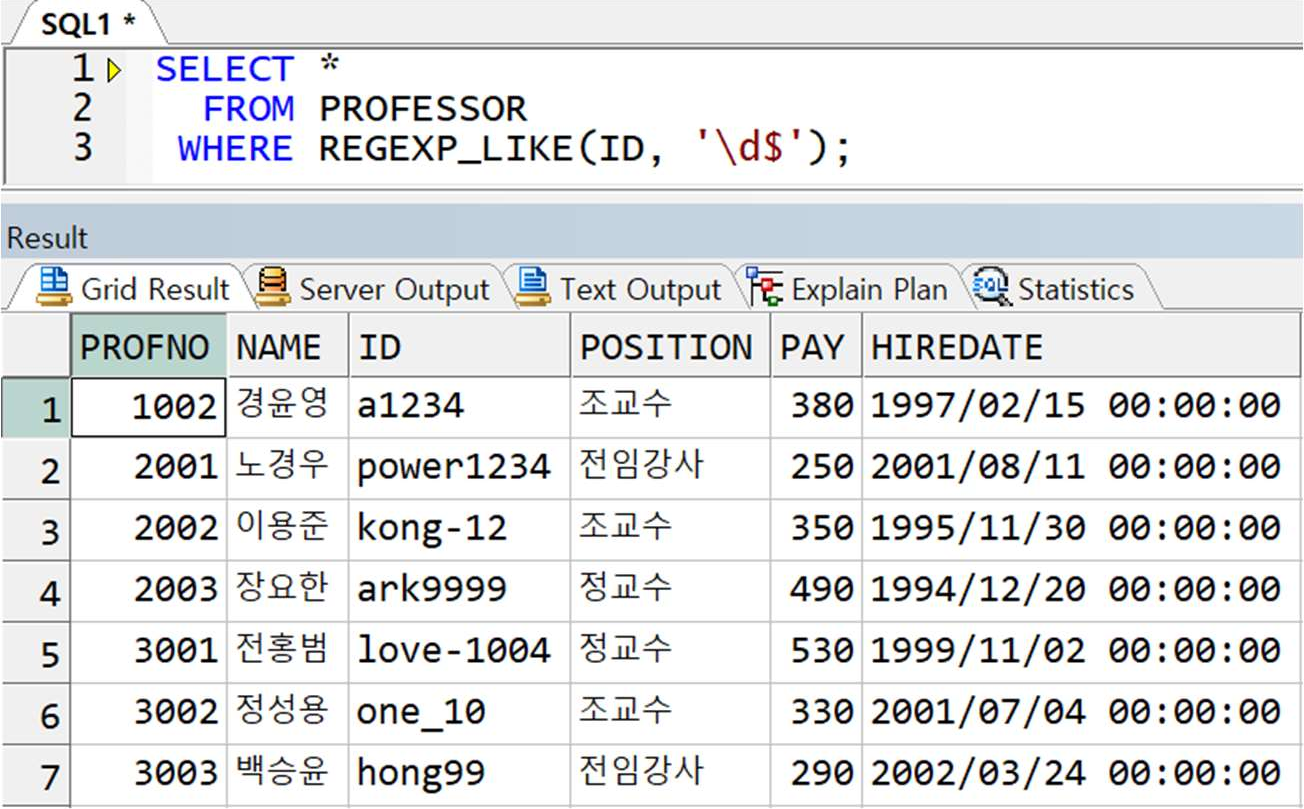
● REGEXP_COUNT
- 주어진 문자열에서 특정패턴의 횟수를 반환
- 옵션 REGEXP_REPLACE 와 동일
- 시작위치 생략 시 처음부터 스캔
** 문법
REGEXP_COUNT (원본, 찾을문자열, 시작위치, [옵션])
예제) ID 값에서의 숫자의 수
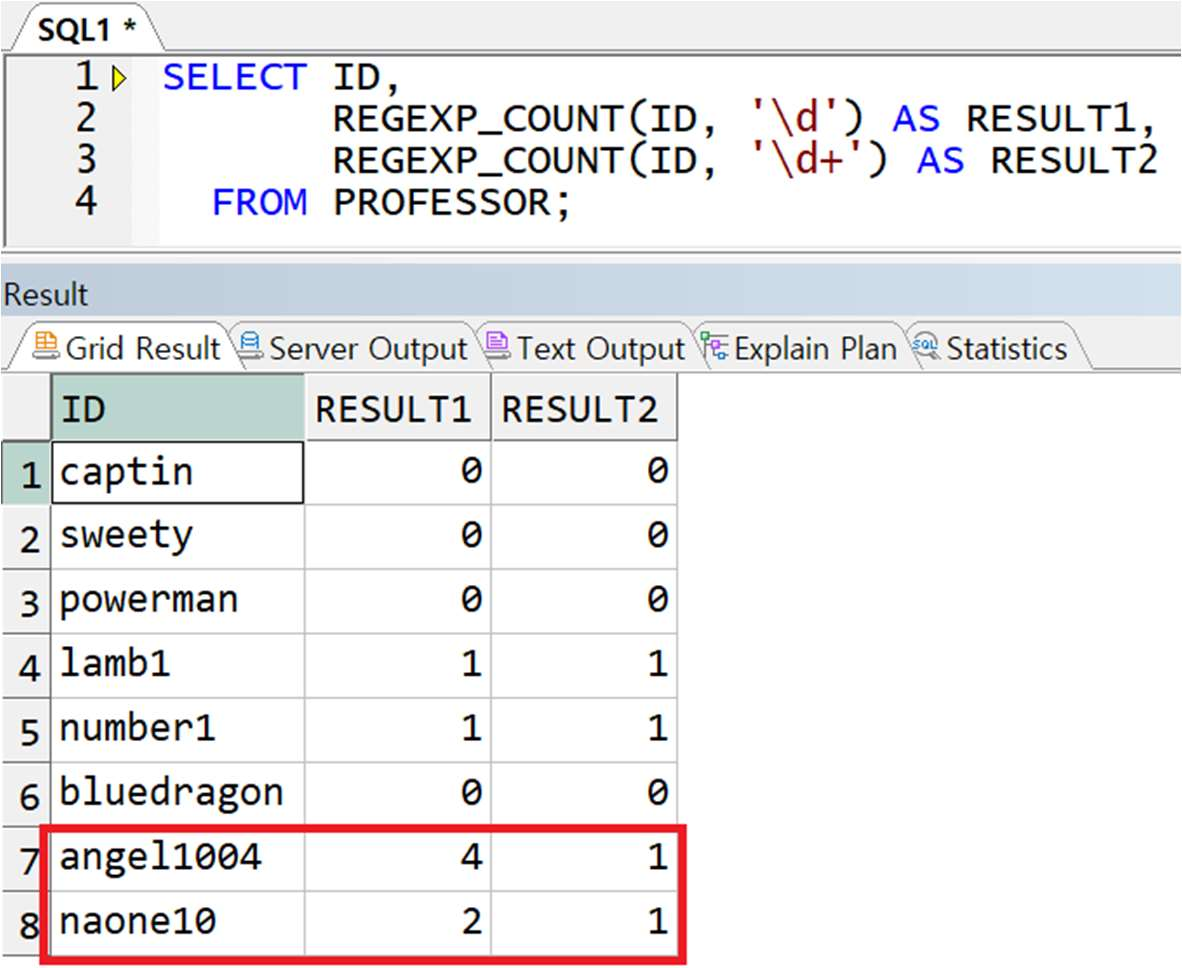
-> \d 는 한 자리수의 숫자를 의미하며 \d+는 연속적인 숫자를 의미. 따라서 COUNT 시 연속적인 숫자를 하나로 취급함
※ 출처 : 홍쌤의 데이터랩 - SQLD
'자격증 > SQLD' 카테고리의 다른 글
| SQLD SQL 기본(19~20) - 17일차 (0) | 2024.11.16 |
|---|---|
| SQLD SQL 기본 및 활용(17~18) - 16일차 (0) | 2024.11.10 |
| SQLD SQL 기본 및 활용 (9~12) - 14일차 (0) | 2024.11.09 |
| SQLD SQL 기본 및 활용(5~8) - 13일차 (0) | 2024.11.03 |
| SQLD SQL 기본 및 활용(1~4) - 12일차 (0) | 2024.10.25 |